Apple Silicon LLM Inference — Five Backends Compared
On Apple Silicon, Qwen3.5-9B was benchmarked across five inference backends — MLX, llama.cpp, Ollama, omlx, and vLLM Metal — under identical conditions. Single-request throughput, prefill scaling, decode-vs-length, and concurrency were measured. omlx is the only backend that actually batches under concurrency. Below: methodology, per-backend results, and which backend suits which scenario.
Setup
The model is Qwen3.5-9B with GatedDeltaNet linear attention. All backends run the same 4-bit quantized weights (MLX-format or Q4_K_M GGUF), on the same Apple Silicon hardware, averaged over three repetitions after a warm-up pass.
Two metrics are reported consistently:
- Decode-only throughput — tokens per second computed as
total_tokens / (end_time - first_token_time). Prefill time is excluded to measure pure generation speed. - Wall-clock TTFT — time from request start to first content token. For HTTP-based backends (omlx, Ollama, llama.cpp) this includes network and serialization overhead; for the MLX library backend it reflects only prompt evaluation. The two are not directly comparable.
Input lengths tested: 512 to 32k tokens. Concurrency levels: 1, 2, and 4 concurrent requests.
Single-Request Throughput
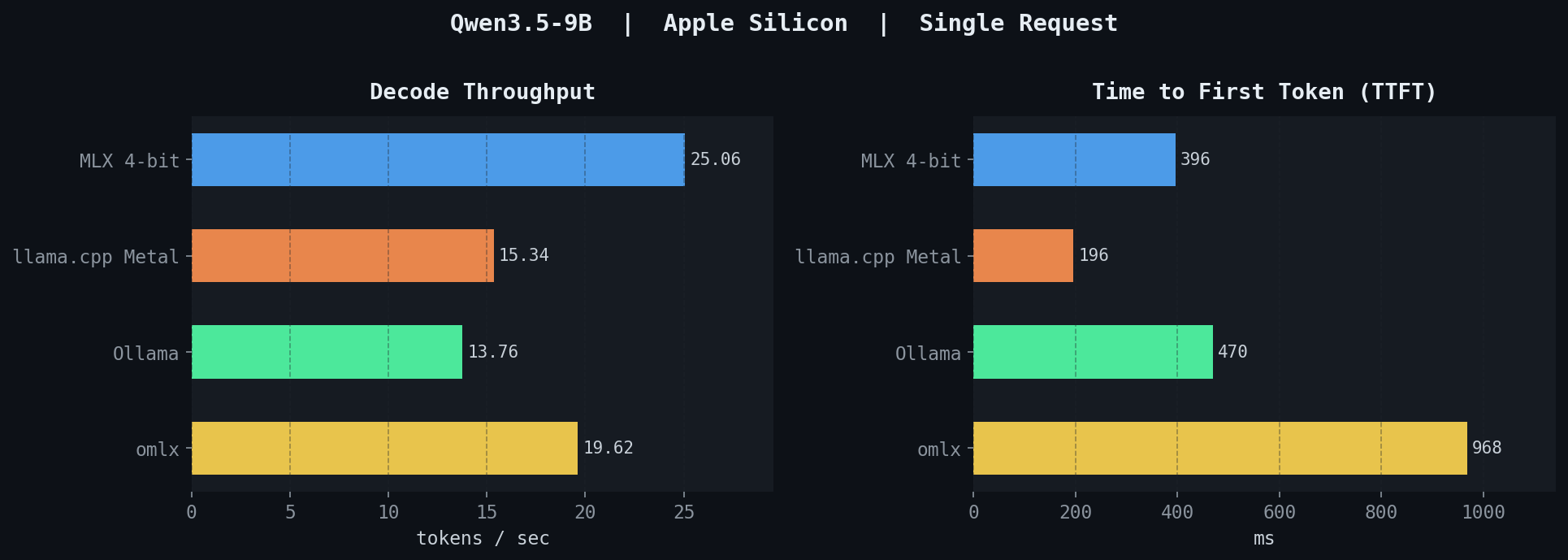
At concurrency 1, the backends separate into three bands.
MLX leads at 25 tok/s with a TTFT of 396 ms. It runs as a direct Python library call — no HTTP server, no scheduler, no serialization layer. The number is the closest measurement to raw hardware capability.
llama.cpp Metal and Ollama cluster together. llama.cpp records 15.3 tok/s with the fastest TTFT of any backend at 196 ms. Ollama, which is llama.cpp-based, sits at 13.8 tok/s with a TTFT of 470 ms — the persistent HTTP server adds a small but consistent per-request cost.
omlx lands at ~20 tok/s with the highest TTFT at 968 ms. Every request enters a continuous-batching scheduler queue before execution, even at concurrency 1. The scheduler introduces a fixed overhead that dominates TTFT at short queue depths. The throughput benefit of that scheduler only becomes visible when multiple requests are in flight simultaneously.
Prefill Scaling
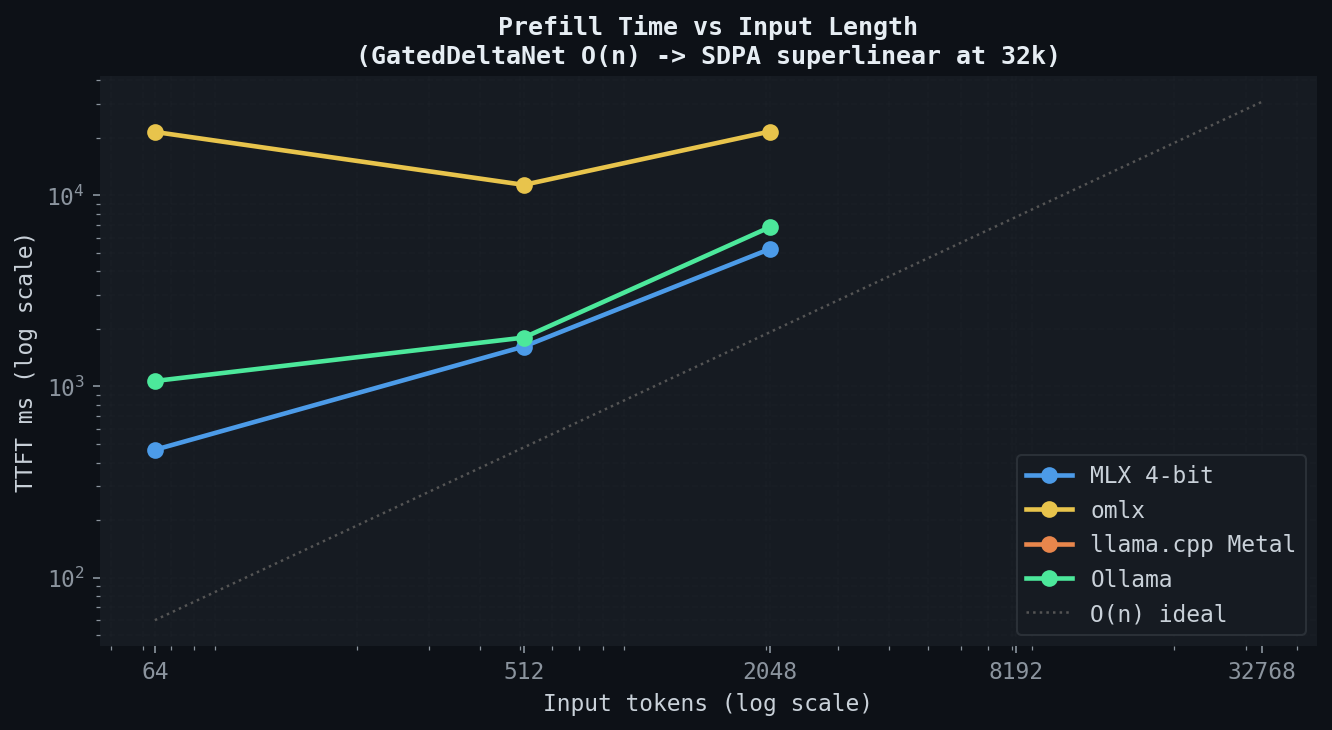
MLX, llama.cpp, and Ollama all exhibit near-linear TTFT growth from 512 tokens through 8k. GatedDeltaNet's recurrent structure processes each token in roughly constant time relative to sequence length, so prefill at 8k costs approximately 16x the prefill at 512 — the linear expectation. Beyond 8k, the curve steepens on all three as the working set exceeds cache-friendly regions.
omlx's TTFT adds a fixed per-request scheduling cost on top of prompt processing. At 512-token inputs this fixed term dominates, which explains the disproportionately high TTFT relative to its decode speed. At longer inputs the scheduling overhead becomes relatively smaller as prompt evaluation time grows, and omlx's per-token prefill cost converges toward MLX's.
Decode Throughput vs Input Length
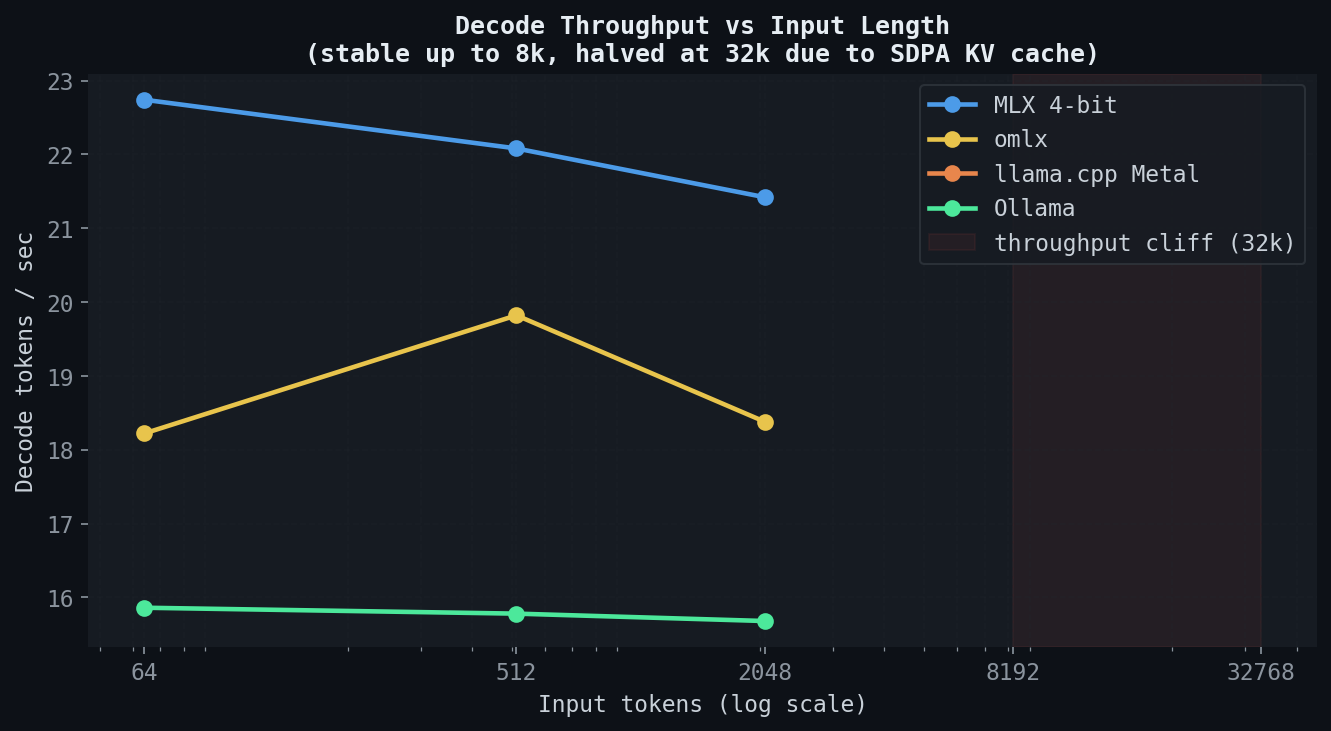
MLX, llama.cpp, and Ollama hold stable decode throughput through 8k input, then approximately halve at 32k. KV cache pressure in unified memory is the likely cause — at 32k, GatedDeltaNet's recurrent state grows large enough to stress memory bandwidth.
omlx runs flat at ~20 tok/s across 512–8k input — about 60% of raw MLX, reflecting the HTTP server's continuous-batching bookkeeping cost. Unlike the other backends, it does not collapse at long context. Its SSD-backed KV cache offloads state that would otherwise overflow, keeping decode throughput stable through input lengths where the others degrade significantly.
Concurrency
When multiple requests arrive simultaneously, a backend can either queue them — processing one at a time while others wait — or batch them, combining requests into a single forward pass for higher aggregate throughput.
Ollama, MLX server, and llama-server are flat under concurrency. NUM_PARALLEL controls queue depth, not batching. Each request executes its own independent forward pass, and aggregate throughput at concurrency 4 is approximately the same as at concurrency 1.
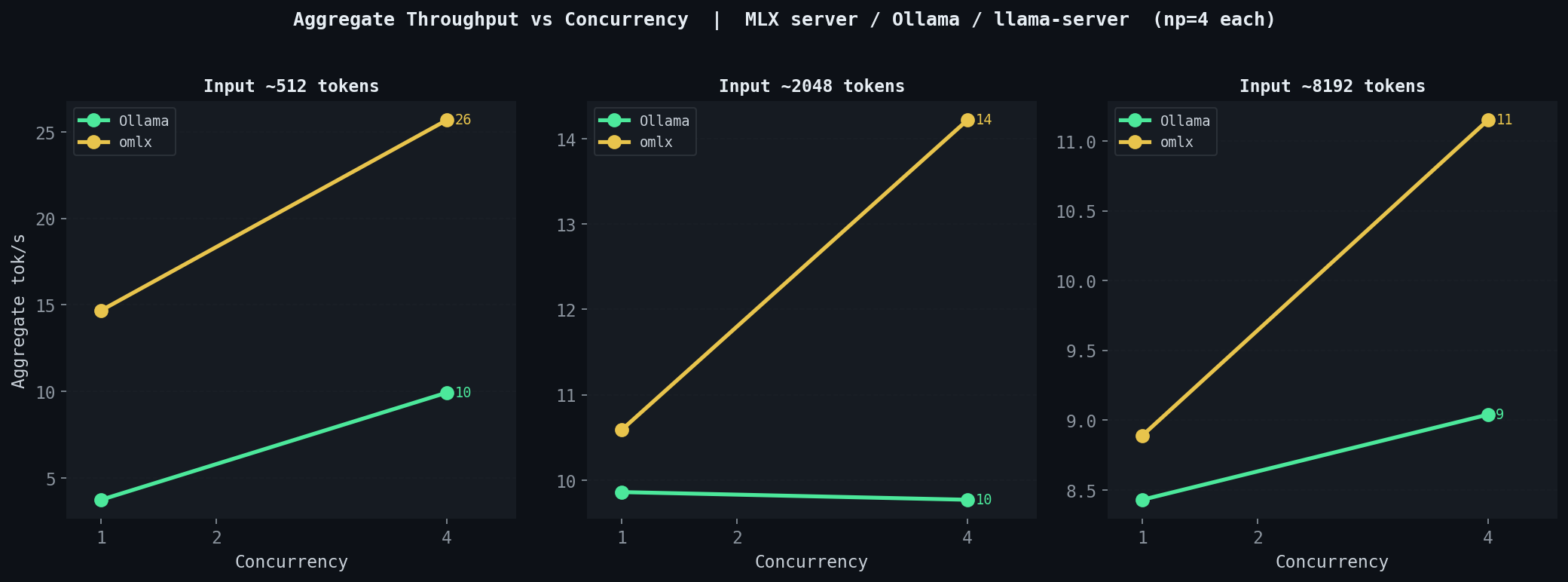
omlx actually batches. Aggregate throughput scales as concurrent requests increase:
- At 512-token input: 15.6 → 21.9 tok/s from concurrency 1 → 4 (1.40x)
- At 2048-token input: 11.2 → 14.4 tok/s from concurrency 1 → 4 (1.29x)
The gains are real but not linear — GatedDeltaNet's recurrent attention does not batch as cleanly as softmax attention does. Requests at different recurrent state positions cannot share computation the way conventional attention batching does. The improvement comes from amortizing scheduler and HTTP overhead across multiple concurrent requests.
TTFT grows with queue depth on every backend, including omlx. Batching increases aggregate throughput while individual request latency rises — a standard trade-off that matters differently depending on the workload.
When to Use What
Single-user local IDE or CLI: MLX is the clear choice — 25 tok/s, no server process, direct library call. If the host application is not Python, llama.cpp Metal offers the lowest TTFT (196 ms) via a clean HTTP API.
Multi-user or multi-request server: omlx is the only backend here that provides genuine request batching — aggregate throughput scales 1.29–1.40x from concurrency 1 to 4 while every other backend stays flat. Its OpenAI-compatible API requires no client-side changes. Running Qwen3.5 requires an upstream patch: omlx 0.3.6 crashes with a Metal stream error on Qwen3.5's RotatingKVCache path, fixed by a ~15-line thread initializer change pending PR to jundot/omlx.
Model catalog convenience: Ollama handles quantization and serving in a single ollama pull. Its numbers (~14 tok/s, 470 ms TTFT) are competitive with llama.cpp Metal when throughput is secondary to operational simplicity.
vLLM Metal: Uses MLX-managed KV cache without paged attention; single-request throughput tracks the MLX range, but the batching advantages that justify vLLM on GPU are not realized in this path.
Closing
GatedDeltaNet linear attention gives Qwen3.5 near-O(n) prefill cost — a genuine advantage on Apple Silicon at 8k context — but the same recurrent structure limits batching efficiency across Ollama, MLX, and llama.cpp, which is why those backends stay flat under concurrency while omlx's gains, though real, remain modest.