Apple Silicon LLM 추론 백엔드 5종 벤치마크
Apple Silicon에서 Qwen3.5-9B를 MLX, llama.cpp Metal, Ollama, omlx, vLLM Metal 다섯 가지 추론 백엔드로 동일 조건에서 벤치마크했습니다. 단일 요청 decode-only throughput과 wall-clock TTFT를 기본 측정치로 삼고, 입력 길이(512~32k 토큰)와 concurrency(1~4 동시 요청)에 따른 응답 변화를 추가로 측정했습니다. 가장 두드러진 결과는 omlx만 실제 batching이 동작한다는 점입니다.
측정 셋업
모델: Qwen3.5-9B, 4-bit 양자화 (MLX 경로는 MLX 형식, llama.cpp/Ollama 경로는 Q4_K_M GGUF)
하드웨어: Apple Silicon (Unified Memory 아키텍처)
백엔드 5종:
| 백엔드 | 실행 방식 | 연결 방식 |
|---|---|---|
| MLX | mlx_lm 라이브러리 직접 호출 |
in-process |
| llama.cpp Metal | llama-server, Q4_K_M GGUF, ngl=99 | HTTP (localhost) |
| Ollama | llama.cpp 기반 서버 | HTTP (localhost) |
| omlx | continuous batching + SSD KV 캐시, OpenAI 호환 | HTTP (localhost:8000) |
| vLLM Metal | MLX 경로 (paged attention 없음) | HTTP (localhost) |
측정 지표 정의:
- Decode-only throughput —
total_tokens / (end_time - first_token_time). 프리필 시간을 제외한 순수 생성 속도를 측정합니다. - Wall-clock TTFT — 요청 시작 시점부터 첫 번째 콘텐츠 토큰을 수신할 때까지의 경과 시간. MLX는 라이브러리 호출 오버헤드(무시 가능) + 프롬프트 평가 + 첫 토큰 생성, llama.cpp/Ollama는 HTTP 요청 + 프롬프트 평가, omlx는 HTTP 요청 + continuous-batching 스케줄러 큐 대기 + 프롬프트 평가 + SSE 프레이밍이 모두 포함됩니다.
전제: HTTP 기반 백엔드(omlx, Ollama, llama.cpp)의 TTFT에는 네트워크 및 직렬화 오버헤드가 포함되므로, MLX 직접 호출과 TTFT를 단순 비교하는 것은 적절하지 않습니다. 각 백엔드의 아키텍처적 특성이 수치에 그대로 반영됩니다.
단일 요청 throughput
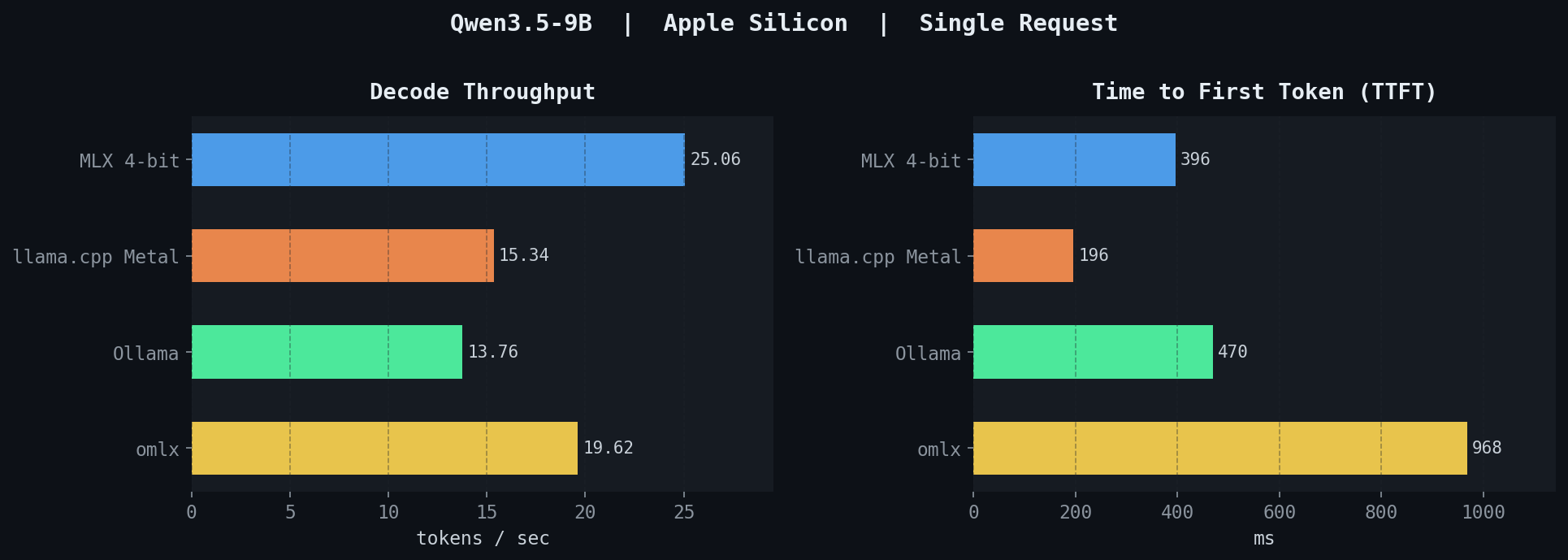
3회 평균을 낸 단일 요청 결과입니다.
| 백엔드 | tokens/sec | TTFT (ms) |
|---|---|---|
| MLX (4-bit) | 25.06 | 396 |
| llama.cpp Metal | 15.34 | 196 |
| Ollama | 13.76 | 470 |
| omlx | 19.62 | 968 |
decode-only throughput은 MLX가 25 tok/s로 선두입니다. 라이브러리를 직접 호출하므로 HTTP 서버 계층의 오버헤드가 전혀 없습니다. omlx는 약 20 tok/s로 중간에 위치하고, llama.cpp와 Ollama는 각각 약 15 tok/s, 14 tok/s로 유사한 수준입니다. 둘 다 같은 llama.cpp 엔진을 사용하므로 throughput 자체는 비슷하게 나옵니다.
TTFT는 반대 양상입니다. llama.cpp Metal이 196ms로 가장 빠르고, MLX가 396ms, Ollama가 470ms입니다. omlx는 968ms로 가장 느립니다. omlx의 높은 TTFT는 설계 때문입니다. 단일 요청에서도 모든 요청이 continuous-batching 스케줄러 큐를 거치며, 여기에 SSE(Server-Sent Events) 프레이밍 오버헤드까지 더해집니다. 이 비용은 단일 요청에서는 순전한 부담이지만, concurrency가 올라갈 때 의미가 달라집니다.
Prefill 스케일링
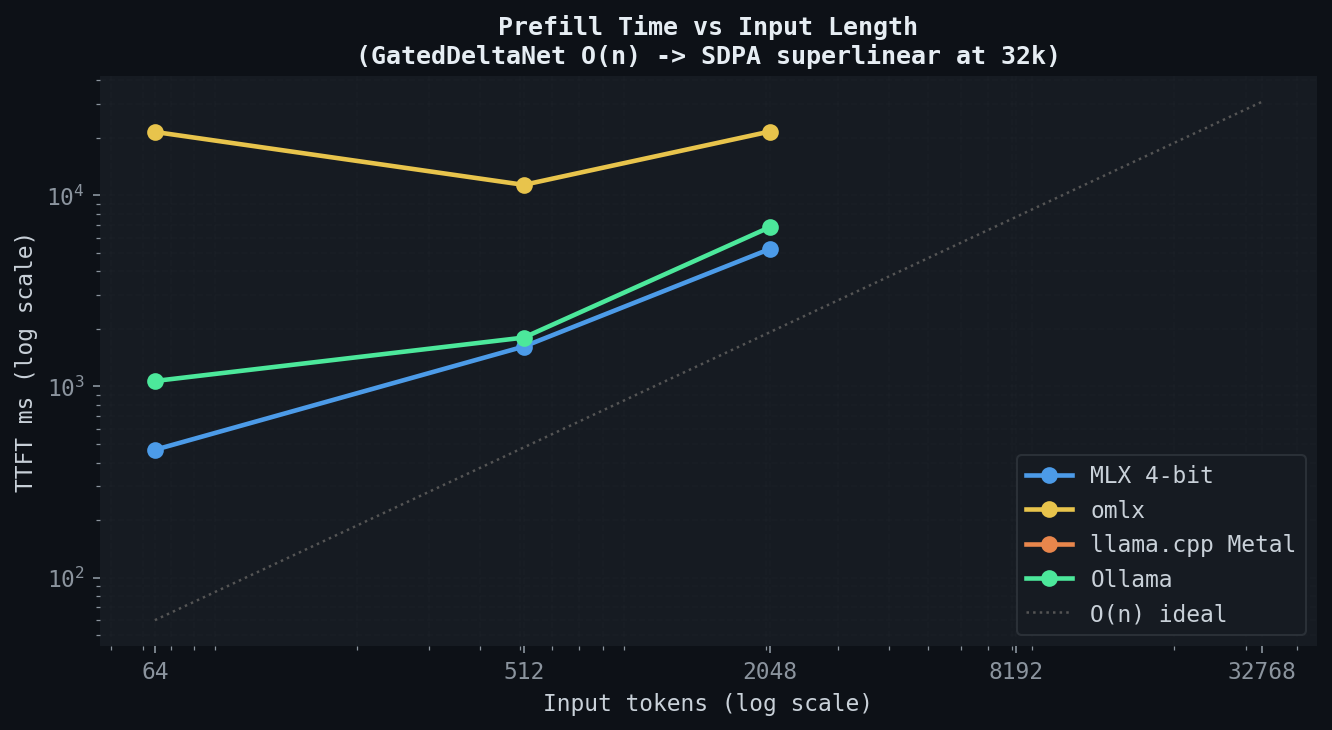
입력 길이를 512토큰부터 8k까지 늘리면서 TTFT(wall-clock 프리필 시간)가 어떻게 변하는지 측정했습니다.
MLX, llama.cpp, Ollama 세 백엔드는 8k까지 입력 길이에 거의 비례해서 TTFT가 증가합니다. Qwen3.5의 GatedDeltaNet linear attention 덕분입니다. 기존 Transformer의 self-attention은 O(n²) 복잡도라 입력이 길어질수록 프리필 비용이 급격히 늘지만, GatedDeltaNet은 O(n) 선형 복잡도로 프리필을 처리합니다. 그 결과 8k 입력까지는 프리필 시간이 입력 길이에 선형적으로 증가합니다.
omlx는 다른 패턴을 보입니다. continuous-batching 경로가 요청마다 고정 스케줄링 비용을 추가하기 때문에, 입력 길이와 무관하게 베이스라인 TTFT가 높은 상태로 시작합니다. 이 고정 비용이 raw MLX에 비해 모든 입력 길이에서 TTFT를 더 높게 유지시킵니다.
Decode 처리량 vs 입력 길이
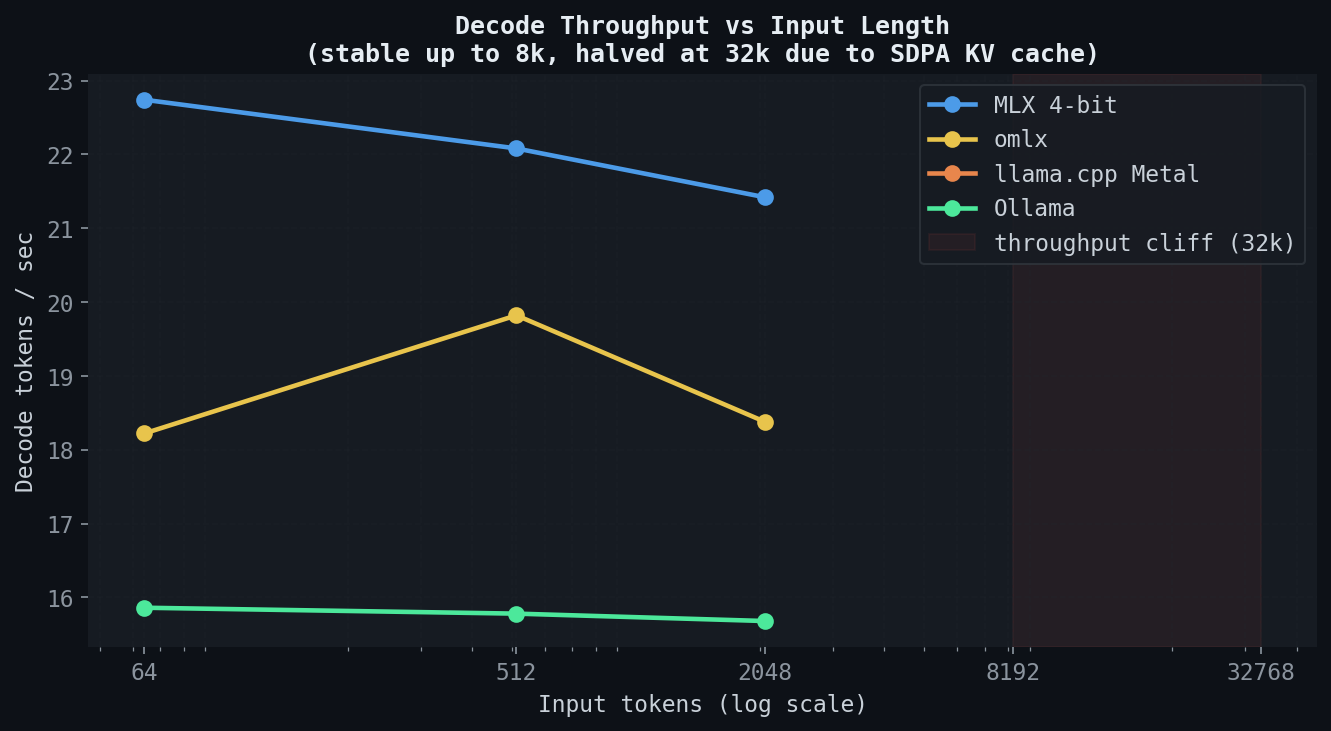
프리필 이후 decode 단계의 throughput이 입력 길이에 따라 어떻게 변하는지 측정했습니다.
MLX, llama.cpp, Ollama는 512~8k 입력에서 decode throughput을 비교적 안정적으로 유지하다가 32k에서 약 절반 수준으로 급감합니다. KV 캐시가 커지면서 메모리 대역폭 압력이 늘어나고, 이것이 decode 속도를 제한합니다.
omlx는 다른 곡선을 그립니다. 512~8k 입력 범위에서 decode throughput이 약 20 tok/s 수준으로 안정적으로 유지됩니다. raw MLX의 약 60% 수준입니다. continuous-batching 스케줄링 오버헤드가 throughput 일부를 잠식하지만, 그 대신 입력 길이가 길어져도 throughput이 크게 무너지지 않습니다. omlx의 SSD 기반 KV 캐시가 긴 컨텍스트에서도 일관된 throughput을 유지하는 데 기여합니다.
Concurrency
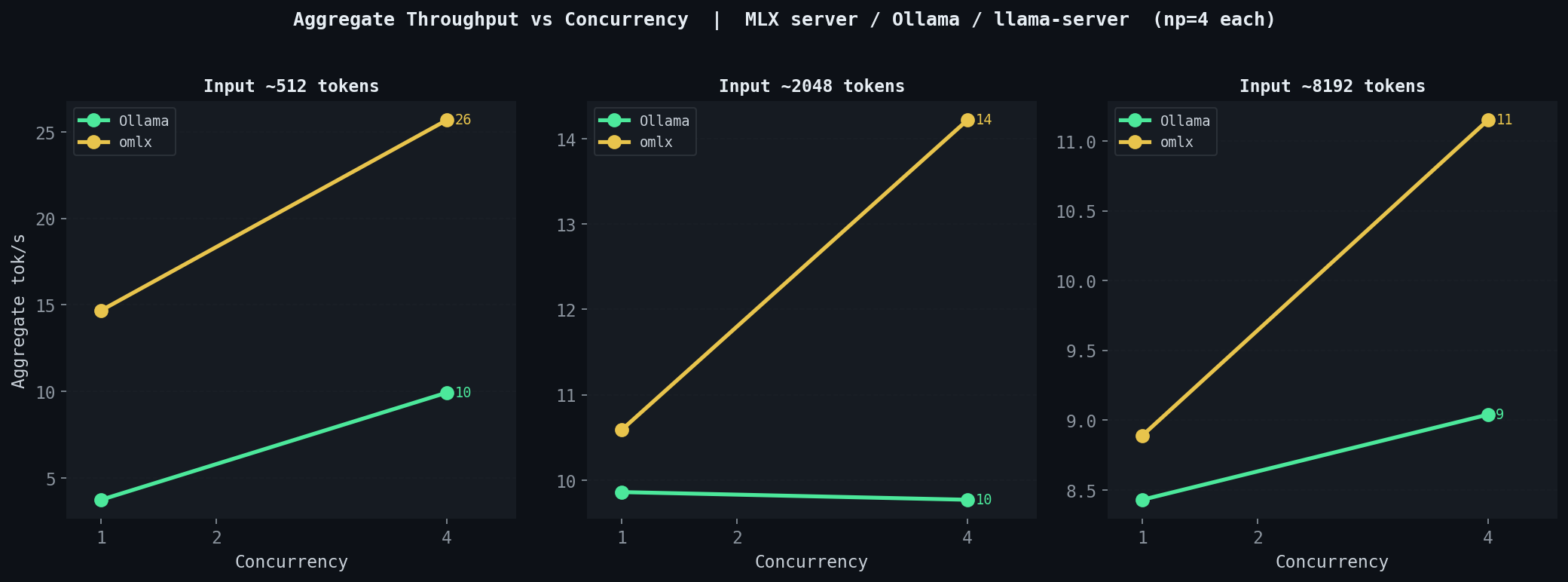
동시 요청 수를 1에서 4로 늘릴 때 각 백엔드의 aggregate throughput이 어떻게 변하는지 측정했습니다.
Ollama, MLX server, llama-server는 concurrency를 올려도 aggregate throughput이 거의 변하지 않습니다. 이 백엔드들의 NUM_PARALLEL이나 동등한 설정은 실제 batching을 수행하는 것이 아니라 큐 깊이(queue depth)만 제어합니다. 요청이 동시에 들어와도 실질적으로는 순차 처리에 가깝고, 총 throughput이 늘지 않습니다.
omlx는 다릅니다.
| 입력 길이 | concurrency 1 | concurrency 4 | 배율 |
|---|---|---|---|
| 512 토큰 | 15.6 tok/s | 21.9 tok/s | 1.40× |
| 2048 토큰 | 11.2 tok/s | 14.4 tok/s | 1.29× |
concurrency 1에서 4로 늘어날 때 512 토큰 입력에서는 15.6 tok/s에서 21.9 tok/s로(1.40배), 2048 토큰 입력에서는 11.2 tok/s에서 14.4 tok/s로(1.29배) aggregate throughput이 증가합니다.
단, TTFT는 모든 백엔드에서 concurrency가 올라갈수록 증가합니다. omlx도 예외가 아닙니다. 큐 깊이가 깊어지면 개별 요청이 스케줄러에서 대기하는 시간이 늘어납니다. batching의 이득은 aggregate throughput에서 나타나고, 개별 요청의 응답 지연은 오히려 길어집니다.
다수 사용자가 동시에 요청을 보내는 환경에서 omlx를 제외한 나머지 백엔드는 요청을 순서대로 처리하는 것과 사실상 동일합니다. omlx만이 진정한 서버 역할을 수행합니다.
어디서 무엇을 쓸지
각 시나리오에 맞는 백엔드를 정리하면 다음과 같습니다.
단일 사용자 로컬 환경 (IDE 플러그인, CLI 도구, 개인 스크립트)
MLX 직접 호출이 가장 빠릅니다. 25 tok/s decode throughput에 HTTP 오버헤드가 없습니다. llama.cpp Metal은 TTFT가 196ms로 가장 짧아 짧은 프롬프트에 대한 응답 체감이 좋습니다. 단일 사용자 환경에서는 concurrency batching이 필요 없으므로 omlx의 장점이 나타나지 않습니다.
다수 사용자 서버 또는 에이전트 오케스트레이터
omlx가 유일한 선택입니다. 나머지 백엔드는 NUM_PARALLEL이 큐 깊이를 조정할 뿐 실제 batching이 없습니다. 여러 에이전트 스텝이 동시에 추론을 요청하는 환경이라면 omlx의 1.29~1.40배 aggregate throughput 이득이 실질적인 차이를 만듭니다.
모델 카탈로그 관리와 운영 편의
Ollama가 유리합니다. ollama pull로 모델을 받고 서비스로 실행하는 워크플로우가 잘 정비되어 있고, OpenAI 호환 API를 제공합니다. throughput이 최고는 아니지만 관리 편의 면에서는 가장 낫습니다.
vLLM Metal
이번 측정에서 vLLM Metal의 단일 요청 수치는 다른 백엔드와 유사한 범위였습니다. Apple Silicon용 paged attention은 아직 실험적 단계(VLLM_METAL_USE_PAGED_ATTENTION=1)이고, MLX 경로는 paged attention 없이 MLX 관리 KV 캐시를 사용합니다. 현시점에서 Apple Silicon 전용 선택지라면 omlx가 production readiness 면에서 앞서 있습니다.
마무리
Qwen3.5의 GatedDeltaNet linear attention은 프리필을 O(n) 복잡도로 만들어 긴 입력에서 상당한 이점을 줍니다. 그런데 이 구조가 동시에 Ollama, MLX server, llama.cpp의 batching을 깨는 원인이기도 합니다. GatedDeltaNet은 상태를 순차적으로 누적하는 방식이라 여러 요청의 KV 상태를 단순히 합산하는 표준 attention batching을 적용하기 어렵습니다. omlx는 continuous-batching 스케줄러를 별도로 구현해 이 제약을 우회합니다.
결국 Apple Silicon에서 Qwen3.5-9B를 운용할 때 단일 사용자 최고 속도는 MLX, 다수 요청을 소화하는 서버 역할은 omlx가 현재로서는 유일한 선택입니다. 두 용도 사이 어딘가에 있다면 llama.cpp Metal이 TTFT와 throughput의 균형 면에서 무난한 중간 선택지가 됩니다.