Speeding up LLM inference with MTP and diffusion
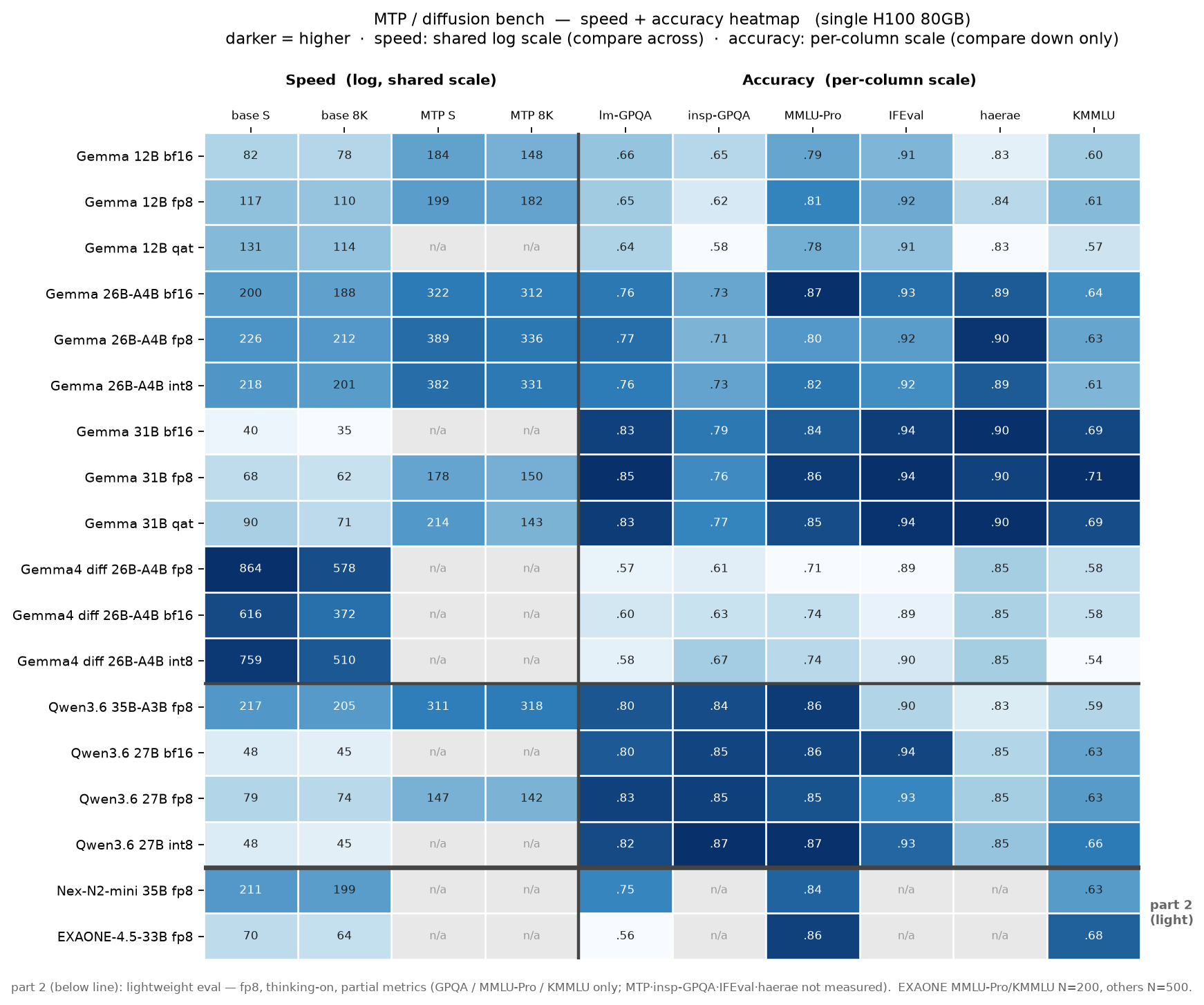
I measured MTP (Multi-Token Prediction, speculative decoding) and diffusion inference on Gemma 4 and Qwen 3.6 across a single H100 80GB. MTP delivered up to 2.62× on dense and 1.43–1.86× on MoE while keeping GPQA-Diamond accuracy effectively unchanged over 198 items (mean Δ ≈ 0). Diffusion ran roughly 4× faster than the equivalent AR baseline but trailed it on every accuracy metric (GPQA −0.20) and does not yet match AR. Everything was measured on top of fp8 quantization.
What was measured and why
The Gemma 4 family includes two dense models (12B and 31B), one MoE (26B total / 4B active), and a diffusion variant (diffusiongemma-26B-A4B). The Qwen 3.6 family includes one dense-hybrid (27B) and an MoE with even fewer active parameters (35B / 3B active). Looking at both families together lets you compare dense vs MoE and AR vs MTP vs diffusion on the same GPU in one pass.
The comparison axes are simple. First, an AR (autoregressive) baseline. Then MTP layered onto the same cell to measure speedup and accuracy. Finally, diffusiongemma placed next to its closest AR analogue (26B-A4B). Precision was fixed at fp8 across the board. A separate sweep had already shown that bf16 / fp8 / int8 / qat accuracy differences sit in the ±0.02–0.05 noise band, so collapsing that axis is justified.
The environment was a single H100 80GB Spot instance in GCP us-central1-a, running vLLM in Docker. Accuracy was measured under thinking-on equal conditions across three frameworks (lm-eval / inspect_ai / HRET) on six metrics: lm-GPQA, inspect-GPQA, MMLU-Pro, IFEval, haerae, and KMMLU.
Setup — model × precision × technique
| Model | Active params | Precision | Techniques measured |
|---|---|---|---|
| Gemma 12B dense | 12B | fp8 | AR, MTP |
| Gemma 26B-A4B MoE | ~4B | fp8 | AR, MTP |
| Gemma 31B dense | 31B | fp8 | AR, MTP |
| diffusiongemma 26B-A4B | ~4B | fp8 | diffusion |
| Qwen 27B dense-hybrid | 27B | fp8 | AR, MTP |
| Qwen 35B-A3B MoE | ~3B | fp8 | AR, MTP |
Speed was measured with one tool — bench_tp.py. The metric is completion_tokens / wall_clock_time (total tok/s) with ignore_eos=True and a fixed 512-token output. Prefix cache off. Short and 8K context conditions were measured separately. Accuracy used thinking-on, max_gen_toks=32768, temp 0.6 / top_p 0.95, with zero truncations.
Serving used per-cell optimal settings (AR max-model-len 40960, util 0.92 / MTP 16384, util 0.85 as representative). Uniform re-serving would have pushed some cells into unrealistic configurations and broken the comparison, so it was more honest to keep the per-cell optimum and disclose the conditions.
AR fp8 baseline
| Model | Speed short/8K (tok/s) | lm-GPQA | MMLU-Pro | IFEval | haerae | KMMLU |
|---|---|---|---|---|---|---|
| Gemma 12B dense | 117 / 110 | 0.652 | 0.814 | 0.916 | 0.844 | 0.610 |
| Gemma 26B-A4B MoE | 226 / 212 | 0.773 | 0.798 | 0.919 | 0.902 | 0.626 |
| Gemma 31B dense | 68 / 62 | 0.849 | 0.862 | 0.944 | 0.898 | 0.708 |
| Qwen 27B dense-hybrid | 79 / 74 | 0.828 | 0.846 | 0.925 | 0.850 | 0.634 |
| Qwen 35B-A3B MoE | 217 / 205 | 0.803 | 0.862 | 0.904 | 0.834 | 0.586 |
This table is the denominator for every speedup that follows. Dense 31B hits the accuracy ceiling at GPQA 0.849 but is the slowest at 68 tok/s. The two low-active-parameter MoEs (26B-A4B and Qwen 35B-A3B) run 3–5× faster than dense 31B while catching up to GPQA 0.77–0.80. Dense as the accuracy ceiling, MoE as the speed-accuracy frontier — the same split holds at a single precision.
MTP — the same pattern in both families
Speedup
| Cell | AR tok/s | MTP tok/s | speedup |
|---|---|---|---|
| Gemma 12B fp8 | 117 | 199 | 1.70× |
| Gemma 26B-A4B fp8 | 226 | 389 | 1.72× |
| Gemma 31B fp8 | 68 | 178 | 2.62× |
| Qwen 27B fp8 | 79 | 147 | 1.86× |
| Qwen 35B-A3B fp8 | 217 | 311 | 1.43× |
The pattern is the same in both families. The denser the model, the bigger the gain. The lower the active parameter count, the smaller the gain. Dense 31B has the slowest AR and therefore the most headroom for spec decode (2.62×); Qwen 35B-A3B already runs fast at the active-3B level and has the least headroom (1.43×). That the sign and magnitude distribution match across both families supports the general claim that MTP gain is determined by AR speed, not by model family.
Accuracy lossless — verified with n=198
The "lossless" claim around MTP is often quoted but rarely tested with a full GPQA run. I measured every MTP cell on GPQA-Diamond full 198 under conditions identical to AR (thinking-on, max_gen_toks 32768, temp 0.6 / top_p 0.95).
| Cell | lm-GPQA MTP / AR (Δ) | insp-GPQA MTP / AR (Δ) |
|---|---|---|
| Gemma 12B fp8 | 0.641 / 0.652 (−0.010) | 0.636 / 0.616 (+0.020) |
| Gemma 26B-A4B fp8 | 0.783 / 0.773 (+0.010) | 0.737 / 0.707 (+0.030) |
| Gemma 31B fp8 | 0.818 / 0.849 (−0.030) | 0.747 / 0.763 (−0.016) |
| Qwen 27B fp8 | 0.818 / 0.828 (−0.010) | 0.854 / 0.854 (0.000) |
| Qwen 35B-A3B fp8 | 0.788 / 0.803 (−0.015) | 0.828 / 0.838 (−0.010) |
Mean Δ is −0.011 for lm and +0.005 for inspect. With per-cell standard error around 0.03, that's inside noise. The largest deviations also flip sign at random (+0.030 alongside −0.030), so there is no systematic loss direction. At n=198, MTP accuracy equals AR.
Bit-level losslessness is refuted
Equal accuracy does not mean equal token sequences. Under greedy decoding (temp=0) I ran 12 prompts with MTP off vs on, and as a control, two AR runs (off vs off2) against each other.
On Gemma 31B fp8 (with a separate drafter), AR matched itself 12/12 (AR is deterministic), but MTP-on matched AR on only 3/12, with all divergence points falling late in the sequence (tokens 483–801). On Qwen 27B fp8 (embedded head), AR itself was already non-deterministic (4/12), and MTP was 0/12.
The cause is FP non-determinism in the verification forward. Differences in FP reduction order during batched verification flip near-tie argmaxes, and divergence shows up hundreds of tokens later. This is floating-point noise, not bias. Accuracy losslessness is formally confirmed (n=198); bit-level token-sequence losslessness is refuted. This fits the "distribution lossless" theory and shows no systematic accuracy loss.
Diffusion — fast, but accuracy still trails AR
| Cell | Speed short/8K (tok/s) | lm-GPQA | MMLU-Pro | IFEval | haerae | KMMLU |
|---|---|---|---|---|---|---|
| diffusiongemma 26B fp8 | 864 / 578 | 0.571 | 0.706 | 0.890 | 0.85 | 0.576 |
| Gemma 26B-A4B fp8 (AR reference) | 226 / 212 | 0.773 | 0.798 | 0.919 | 0.902 | 0.626 |
The top speed of 864 tok/s is roughly 4× the AR equivalent at the same active-4B / 26B scale. But accuracy is lower than AR on every metric. GPQA drops by −0.20 and MMLU-Pro by −0.09 (the reasoning tasks take the worst of it), while haerae (−0.05), KMMLU (−0.05), and IFEval (−0.03) are smaller but still consistent losses — nothing held even, nothing improved. On accuracy alone, diffusion does not yet match AR.
The same pattern shows in context length. On NIAH (Needle In A Haystack), Gemma and Qwen AR cleared all three needle positions (10/50/90% depth) at ~241K context (3/3). Diffusion only managed 2/3 at 32K–48K, and the failure was always at the 90% depth — the tail end of the sequence. Block diffusion's inability to recover sequence-tail needles is the same shape as its reasoning weakness. The bottom line: diffusion currently trails AR in accuracy across the board. It is practical only where that accuracy loss is small and a 4× speedup is worth paying for — latency-bound bulk work like summarization or translation — while reasoning and long-document tail recall stay with AR.
Things that broke the measurement twice
The clean results above did not come out clean. Two measurement bugs nearly inverted the narrative, and both were discovered only after a full run completed.
Streaming measurement under-counted MTP by 3×
The first attempts used vLLM's streaming decode_tok/s to measure MTP. The result was "acceptance length is 100% but speedup is invisible." On Qwen it went further: "0.44× — MTP is a loss."
The misdiagnosis was "MoE is bad for spec decode — the verification cost eats the gain." The real cause was elsewhere. Streaming decode_tok/s counts tokens when they reach the client, but spec decode commits multiple tokens per verification forward in bursts. The streaming meter doesn't see those bursts, so the average flattens. Cross-checking against vLLM's "Mean acceptance length" log line showed the gain was actually happening.
The fix was to rip out the measurement and replace it. Re-running with non-streaming total throughput (fixed output / wall clock) flipped "0.44× loss" into 2.6–3.0× gain. A single instrumentation bug had completely invalidated the initial Gemma and Qwen conclusions. One-line lesson: never measure spec decode or MTP with a streaming token-rate metric.
The thinking-on answer-extraction trap
The second bug was on the grader side. When thinking is enabled, the model writes the answer once in its reasoning summary and again in the final body. If the grader picks the first option-letter in the reasoning summary as "the answer," the score collapses to zero or below random. You only find out after the full run finishes and you open the result CSV.
| Framework / bench | Symptom | Real cause | Fix |
|---|---|---|---|
| lm-eval GPQA | accuracy 0.0 | strict-match grabs the reasoning preamble | use flexible-extract first |
| HRET haerae | 0.146 (below random) | string_match catches the first option in the thinking summary | custom runner, extract the last (X) — score jumped to 0.844 |
| inspect IFEval | empty output | missing dep + metric is named final_acc, not accuracy |
install dep + fix grep pattern |
The shared fix is to grab "the last answer-letter in the body," not "the first option in the reasoning summary." On HRET, one cell went from 0.146 to 0.844 — a 0.7-point jump driven entirely by extraction, not model behavior.
The most expensive time-saver to come out of this was a single discipline. Run --limit 5 smoke before any full run. Five items per cell, per benchmark, just enough to confirm the score is sane (> random, not blank). Extraction bugs surface in five items, not in a multi-hour full run.
Two broken measurements nearly inverted the narrative. Keeping these failures in the record (the "no-hiding" principle) is the cheapest insurance against the next person walking into the same traps.
Conclusion and workload guide
- MTP delivered consistent speedups across both model families: dense 2.62× and MoE 1.43–1.86×, with accuracy losslessness confirmed on n=198 GPQA-Diamond (mean Δ ≈ 0). The token sequence is non-deterministic but accuracy is not lost.
- Diffusion is 4× faster but its accuracy trails AR on every metric (GPQA −0.20, and even language tasks by −0.03 to −0.05). It pays off only where that accuracy loss is acceptable and speed is the priority; reasoning and long-document tails stay with AR.
- Low-active-parameter MoE leads on the speed-accuracy trade-off. Qwen 35B-A3B fp8 + MTP runs 311 tok/s with GPQA 0.788 — 0.06 below dense 31B (0.849) in accuracy but 4.6× the speed.
| Workload | Best cell |
|---|---|
| Hard reasoning (science / math) | Gemma 31B dense fp8 + MTP (2.62×) — accuracy ceiling |
| General speed-accuracy balance | Qwen 35B-A3B / Gemma 26B-A4B fp8 + MTP |
| Korean understanding / chat / summarization | Gemma 26B-A4B fp8 (accuracy first) |
| Low-latency bulk (accuracy loss acceptable) | diffusiongemma fp8 (864 tok/s; lower accuracy across the board) |
| Long documents (~256K) | AR Gemma / Qwen — diffusion is weak at the tail |
This post covers the core. Full precision sweeps (bf16 / fp8 / int8 / qat), 4-bit pre-quantization (GPTQ / AWQ / NVFP4), 256K context length verification, and the second-tier league of 6 additional models (EXAONE-4.5, Nex-N2, VibeThinker-3B, and others) are in the full 7-chapter report. The master dataset (250 rows) is in results_consolidated.csv.