MTP와 diffusion으로 LLM 추론 가속하기
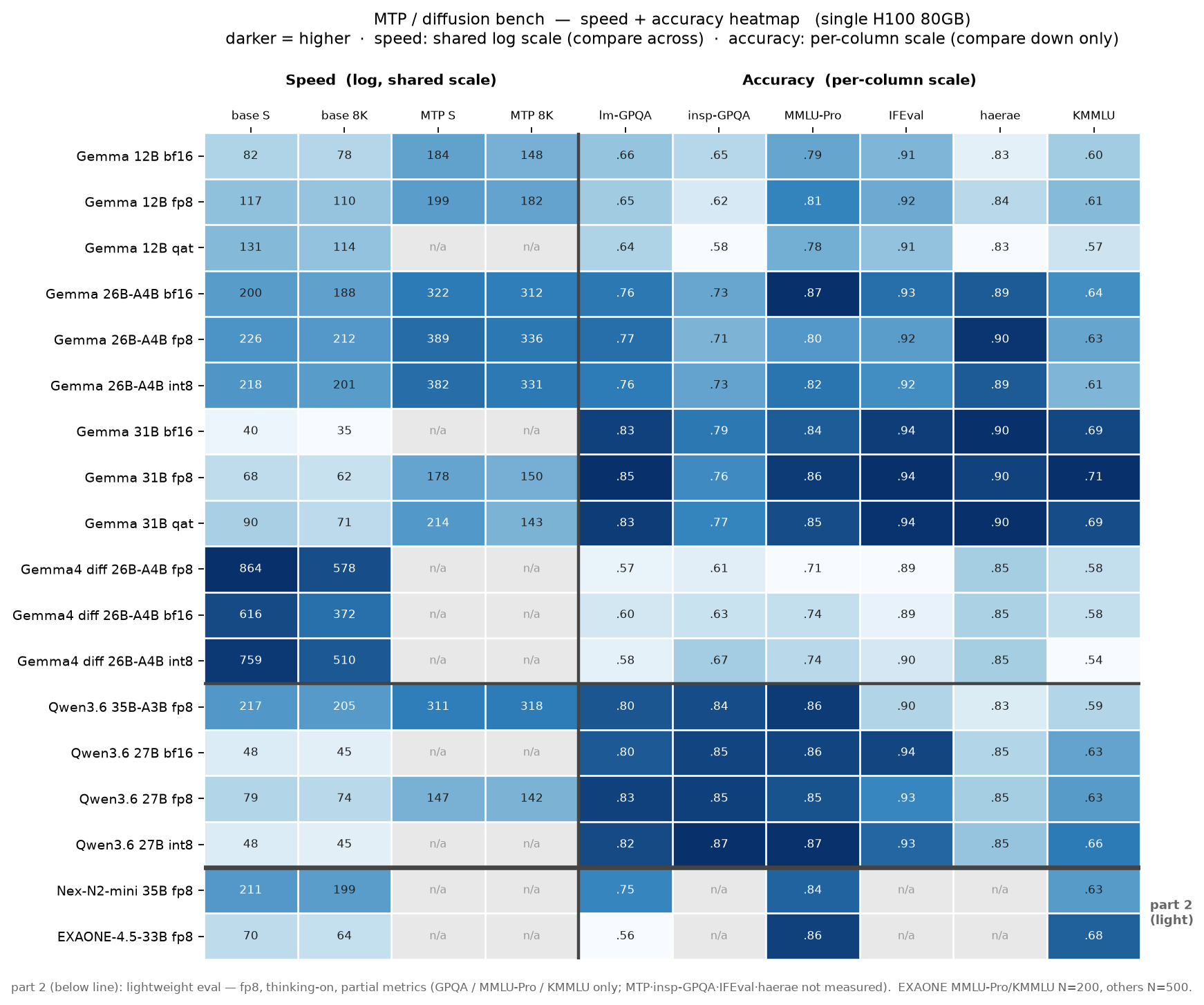
Gemma 4와 Qwen 3.6 두 계열에서 MTP(Multi-Token Prediction, speculative decoding)와 diffusion 추론을 H100 80GB 한 장에 올려 측정했습니다. MTP는 dense에서 최대 2.62배, MoE에서 1.43~1.86배 가속을 주면서 GPQA-Diamond 198문항 기준 정확도가 사실상 같았고(평균 Δ ≈ 0), diffusion은 동급 AR보다 약 4배 빠르지만 정확도가 전 지표에서 낮아 아직 AR에 못 미쳤습니다(GPQA −0.20). 모두 fp8 양자화 위에서 측정했습니다.
무엇을 왜 측정했는가
Gemma 4 계열에는 dense 3종(12B / 31B)과 MoE 1종(26B 중 활성 4B), 그리고 diffusion 변종(diffusiongemma-26B-A4B)이 모두 있습니다. Qwen 3.6 계열에는 dense-hybrid 1종(27B)과 활성 파라미터가 더 적은 MoE(35B 중 활성 3B)가 있습니다. 두 계열을 같이 보면 dense 대 MoE, AR 대 MTP 대 diffusion이라는 축을 같은 GPU에서 한 번에 비교할 수 있습니다.
비교축은 단순합니다. AR(autoregressive) 기준선을 먼저 깐 뒤, 같은 셀에 MTP를 얹어 speedup과 정확도를 보고, 마지막으로 diffusiongemma를 AR 동급(26B-A4B)과 옆에 세웁니다. 정밀도는 전부 fp8로 통일했습니다. 별도 sweep에서 bf16 / fp8 / int8 / qat의 정확도 차이가 ±0.02~0.05 노이즈 수준이라는 점을 확인한 뒤 변수를 하나로 묶은 결과입니다.
측정 환경은 GCP us-central1-a의 H100 80GB Spot 한 장, vLLM docker, 3개 평가 프레임워크(lm-eval / inspect_ai / HRET)에서 6개 지표(lm-GPQA, insp-GPQA, MMLU-Pro, IFEval, haerae, KMMLU)를 thinking-on 동등조건으로 돌렸습니다.
셋업 — 모델 × 정밀도 × 기법
| 모델 | 활성 파라미터 | 정밀도 | 기법 측정 |
|---|---|---|---|
| Gemma 12B dense | 12B | fp8 | AR, MTP |
| Gemma 26B-A4B MoE | ~4B | fp8 | AR, MTP |
| Gemma 31B dense | 31B | fp8 | AR, MTP |
| diffusiongemma 26B-A4B | ~4B | fp8 | diffusion |
| Qwen 27B dense-hybrid | 27B | fp8 | AR, MTP |
| Qwen 35B-A3B MoE | ~3B | fp8 | AR, MTP |
속도 측정 도구는 bench_tp.py로 통일했습니다. 지표는 completion_tokens / wall_clock_time의 total tok/s이고, ignore_eos=True로 출력을 고정 512 토큰으로 끊었습니다. 프리픽스 캐시는 끈 상태로 short / 8K 컨텍스트 두 조건을 따로 잽니다. 정확도는 thinking-on, max_gen_toks=32768, temp 0.6 / top_p 0.95를 동일하게 적용해 절단 0건으로 측정했습니다.
서빙은 셀별 최적값(대표적으로 AR max-model-len 40960, util 0.92 / MTP 16384, util 0.85)으로 잡았습니다. 균일 재서빙은 일부 셀을 비현실적으로 만들어 비교가 깨지기 때문에, 셀별 최적 구성을 그대로 두고 조건을 명시하는 방식이 더 정직했습니다.
AR fp8 기준선
| 모델 | 속도 short/8K (tok/s) | lm-GPQA | MMLU-Pro | IFEval | haerae | KMMLU |
|---|---|---|---|---|---|---|
| Gemma 12B dense | 117 / 110 | 0.652 | 0.814 | 0.916 | 0.844 | 0.610 |
| Gemma 26B-A4B MoE | 226 / 212 | 0.773 | 0.798 | 0.919 | 0.902 | 0.626 |
| Gemma 31B dense | 68 / 62 | 0.849 | 0.862 | 0.944 | 0.898 | 0.708 |
| Qwen 27B dense-hybrid | 79 / 74 | 0.828 | 0.846 | 0.925 | 0.850 | 0.634 |
| Qwen 35B-A3B MoE | 217 / 205 | 0.803 | 0.862 | 0.904 | 0.834 | 0.586 |
이 표가 이후 모든 speedup의 분모입니다. dense 31B가 GPQA 0.849로 정확도 천장을 찍지만 속도는 68 tok/s로 가장 느립니다. 반대로 활성 파라미터가 적은 MoE 2종(26B-A4B, Qwen 35B-A3B)은 dense 31B 대비 3~5배 빠르면서 GPQA가 0.77~0.80으로 따라붙습니다. dense는 정확도 천장 역할, MoE는 속도-정확도 프론티어 역할이라는 구도가 fp8 한 정밀도에서도 그대로 나타납니다.
MTP — 두 계열에서 같은 패턴이 나왔다
Speedup
| 셀 | AR tok/s | MTP tok/s | speedup |
|---|---|---|---|
| Gemma 12B fp8 | 117 | 199 | 1.70× |
| Gemma 26B-A4B fp8 | 226 | 389 | 1.72× |
| Gemma 31B fp8 | 68 | 178 | 2.62× |
| Qwen 27B fp8 | 79 | 147 | 1.86× |
| Qwen 35B-A3B fp8 | 217 | 311 | 1.43× |
패턴이 두 계열에서 같습니다. dense일수록 이득이 크고, MoE일수록 이득이 작습니다. AR이 느린 dense 31B는 spec decode가 끼어들 헤드룸이 가장 크고(2.62×), 이미 활성 파라미터가 적어 빠른 MoE Qwen 35B-A3B는 헤드룸이 가장 좁습니다(1.43×). 두 계열에서 부호와 크기 분포가 같다는 사실은 "MTP 이득은 모델군이 아니라 AR 속도가 결정한다"는 일반화 명제를 뒷받침합니다.
정확도 무손실 — n=198로 정식 검증
MTP의 "무손실"은 흔히 인용되지만 실제 GPQA 풀런으로 검증한 사례는 드뭅니다. 모든 MTP 셀에 대해 AR과 완전히 같은 조건(thinking-on, max_gen_toks 32768, temp 0.6 / top_p 0.95)으로 GPQA-Diamond full 198을 직접 측정했습니다.
| 셀 | lm-GPQA MTP / AR (Δ) | insp-GPQA MTP / AR (Δ) |
|---|---|---|
| Gemma 12B fp8 | 0.641 / 0.652 (−0.010) | 0.636 / 0.616 (+0.020) |
| Gemma 26B-A4B fp8 | 0.783 / 0.773 (+0.010) | 0.737 / 0.707 (+0.030) |
| Gemma 31B fp8 | 0.818 / 0.849 (−0.030) | 0.747 / 0.763 (−0.016) |
| Qwen 27B fp8 | 0.818 / 0.828 (−0.010) | 0.854 / 0.854 (0.000) |
| Qwen 35B-A3B fp8 | 0.788 / 0.803 (−0.015) | 0.828 / 0.838 (−0.010) |
평균 Δ는 lm 기준 −0.011, inspect 기준 +0.005입니다. 셀당 standard error가 약 0.03이라는 점을 고려하면 노이즈 안에 있습니다. 최대 편차도 부호가 무작위(+0.030과 −0.030이 함께 등장)라 체계적 손실 방향이 보이지 않습니다. n=198에서 MTP 정확도는 AR과 같습니다.
"비트 무손실"은 반증된다
정확도가 같다고 토큰열까지 같지는 않습니다. greedy(temp=0)에서 같은 프롬프트 12개를 MTP off-vs-on으로 돌리고, 대조군으로 같은 AR을 두 번(off-vs-off2) 돌려 비교했습니다.
Gemma 31B fp8(별도 드래프터)에서 AR끼리는 12/12 완전 일치(AR이 결정적)였지만 MTP-on은 12개 중 3개만 동일했고 분기점은 모두 토큰 483~801 사이의 늦은 위치였습니다. Qwen 27B fp8(임베디드 head)은 AR 자체가 이미 비결정이라 4/12, MTP는 0/12였습니다.
원인은 검증 forward의 FP 비결정성입니다. 배치 검증의 FP 리덕션 순서 차이로 근소동률 argmax가 뒤집히고, 그 결과 수백 토큰 뒤에 갈라집니다. 편향이 아니라 부동소수점 잡음입니다. 정확도 무손실은 정식 확정(n=198), 토큰열 비트 무손실은 반증입니다. "분포 무손실" 이론과 정합하며, 체계적 정확도 손실 징후도 없습니다.
Diffusion — 4배 빠르지만 정확도는 아직 부족하다
| 셀 | 속도 short/8K (tok/s) | lm-GPQA | MMLU-Pro | IFEval | haerae | KMMLU |
|---|---|---|---|---|---|---|
| diffusiongemma 26B fp8 | 864 / 578 | 0.571 | 0.706 | 0.890 | 0.85 | 0.576 |
| Gemma 26B-A4B fp8 (AR 참조) | 226 / 212 | 0.773 | 0.798 | 0.919 | 0.902 | 0.626 |
최속 864 tok/s는 같은 26B 활성 4B AR보다 약 4배 빠른 수치입니다. 그런데 정확도는 모든 지표에서 AR보다 낮습니다. GPQA −0.20, MMLU-Pro −0.09로 추론 과제에서 특히 크게 떨어지고, 한국어 haerae −0.05, KMMLU −0.05, IFEval −0.03으로 언어·지시 과제에서도 작지만 일관되게 낮습니다. 동률이거나 개선된 지표는 하나도 없습니다. 정확도만 보면 diffusion은 아직 AR에 못 미칩니다.
같은 결이 컨텍스트 길이에도 나타납니다. NIAH(Needle In A Haystack) 테스트에서 Gemma·Qwen AR은 ~241K 길이에서 depth 10/50/90% 세 위치 모두 회수(3/3)에 성공했지만, diffusion은 32K~48K에서 2/3에 머물렀고 실패는 항상 말단 depth 90%에서 발생했습니다. 블록 디퓨전이 시퀀스 말단을 회수하지 못하는 특성은 추론 약점과 같은 결입니다. 정리하면 diffusion은 현재 정확도에서 AR을 전반적으로 밑돕니다. 정확도 손실이 작은 과제에서 4배 속도가 그 손실을 감수할 만한 대량 저지연 워크로드(요약, 번역 등)에 한해 실용적이고, 추론과 긴 문서 말단 회수는 AR로 남겨야 합니다.
시행착오 — narrative를 두 번 뒤집은 측정 결함
위 결과는 깨끗하게 도출되지 않았습니다. 두 종류의 측정 결함이 narrative 전체를 뒤집을 뻔했고, 둘 다 풀런이 끝난 뒤에야 발견됐습니다.
Streaming 측정이 MTP를 3배 과소측정한 사건
처음에는 vLLM의 streaming decode_tok/s로 MTP 가속을 쟀습니다. 결과는 "acceptance length 100%인데 가속이 보이지 않는다"였습니다. Qwen 쪽에서는 한 단계 더 나가 "0.44× 손해"라는 수치까지 나왔습니다.
오진은 "MoE는 spec decode에 불리하다 — 검증 비용이 이득을 잡아먹는다"였습니다. 진짜 원인은 다른 곳에 있었습니다. streaming decode_tok/s는 토큰이 클라이언트로 흘러간 시점을 기준으로 계산하는데, spec decode는 여러 토큰을 한 번의 검증 forward로 묶어 커밋합니다. 이 버스트 커밋을 streaming 지표가 잡지 못해 평균이 깎입니다. vLLM 로그의 "Mean acceptance length"로 교차검증하니 실제로는 이득이 발생하고 있었습니다.
해법은 측정 방식 전면 교체였습니다. non-streaming 총처리량(고정 출력 / wall-clock)으로 다시 돌렸더니 "0.44× 손해"가 2.6~3.0× 이득으로 반전됐습니다. 단일 측정 결함이 Gemma·Qwen 양쪽 초기 결론을 통째로 무효화했습니다. 교훈은 한 줄입니다 — spec decode와 MTP는 절대 streaming 토큰율로 측정하지 말 것.
thinking-on의 답 추출 함정
두 번째 함정은 채점기 쪽입니다. thinking을 켜면 모델이 추론 요약부에 정답을 한 번 적었다가 본문에서 다시 정리하는데, 채점기가 추론 요약부의 첫 옵션을 최종답으로 잡으면 점수가 0이나 random 미만으로 떨어집니다. 풀런이 끝나고 결과 CSV를 열어 보고 나서야 발견됩니다.
| 프레임워크 / 벤치 | 증상 | 진짜 원인 | 해법 |
|---|---|---|---|
| lm-eval GPQA | accuracy 0.0 | strict-match가 추론 서두를 점수로 집음 | flexible-extract 우선 |
| HRET haerae | 0.146 (random 미만) | string_match가 thinking 요약부 첫 옵션 오집 | 자체 러너, 마지막 (X) 추출 → 0.844 |
| inspect IFEval | 결과 공백 | 의존성 누락 + metric명이 accuracy가 아니라 final_acc |
dep 설치 + grep 패턴 보정 |
공통 해법은 "추론 요약부 첫 옵션"이 아니라 "본문 마지막 answer-letter"를 잡는 추출이었습니다. HRET에서는 한 셀이 0.146에서 0.844로 0.7 가까이 뛰었습니다. 모델 성능이 바뀐 게 아니라 채점기가 답을 못 찾고 있었던 것입니다.
여기서 가장 비싼 시간을 살린 규율 하나가 나왔습니다. 풀런 전 --limit 5 스모크. 각 벤치를 셀 하나씩 5문항만 먼저 돌려 점수가 sane(>random, 공백 아님)인지 확인한 뒤에만 풀런으로 넘어갑니다. 추출 버그는 수 시간짜리 풀런 뒤가 아니라 5문항에서 잡힙니다.
깨진 측정 두 건이 결과 narrative 자체를 뒤집을 뻔했습니다. 이런 함정을 숨기지 않고 남기는 기록(no-hiding)은 다음 측정자가 같은 함정에 빠지지 않게 하는 가장 값싼 보험입니다.
결론과 워크로드 가이드
- MTP는 두 모델 계열에서 일관된 가속을 줬습니다. dense 2.62×, MoE 1.43~1.86×, 그리고 n=198 GPQA-Diamond에서 정확도 무손실이 확정됐습니다(평균 Δ ≈ 0). 토큰열은 비결정이지만 정확도 손실은 없습니다.
- diffusion은 4배 빠른 대신 정확도가 모든 지표에서 AR보다 낮습니다(GPQA −0.20, 언어 과제도 −0.03~−0.05). 속도가 그 정확도 손실을 감수할 만한 대량 저지연 워크로드에서만 실용적이고, 추론과 긴 문맥 말단에는 부적합합니다.
- 활성 파라미터가 적은 MoE가 속도-정확도 균형에서 가장 유리합니다. Qwen 35B-A3B fp8 + MTP는 311 tok/s에 GPQA 0.788로, dense 31B(0.849)보다 정확도는 0.06 낮지만 속도가 4.6배입니다.
| 워크로드 | 최적 셀 |
|---|---|
| 하드추론(과학·수학) | Gemma 31B dense fp8 + MTP (2.62×) — 정확도 천장 |
| 범용 속도-정확도 균형 | Qwen 35B-A3B / Gemma 26B-A4B fp8 + MTP |
| 한국어 이해·대화·요약 | Gemma 26B-A4B fp8 (정확도 우선) |
| 저지연 대량(정확도 손실 감수 가능) | diffusiongemma fp8 (864 tok/s, 전 지표 정확도 하락) |
| 긴 문서(장문맥 ~256K) | AR Gemma/Qwen — diffusion은 말단 회수 약 |
이 글은 골자만 다뤘습니다. 양자화 sweep(bf16 / fp8 / int8 / qat), 4-bit 사전양자화(GPTQ / AWQ / NVFP4), 컨텍스트 길이 256K 검증, 그리고 2부 리그 6모델(EXAONE-4.5, Nex-N2, VibeThinker-3B 등) 측정은 전체 보고서 7장에 정리해 두었습니다. 마스터 데이터(250행)는 results_consolidated.csv에서 확인할 수 있습니다.