Long-Context Evaluation — NIAH and Lost in the Middle
Needle-in-a-Haystack (NIAH) is a standard benchmark for measuring an LLM's ability to use a long context window. NIAH scores, however, are not the same as long-context capability — Liu et al. (2023)'s "Lost in the Middle" study reported a U-shaped recall curve where models systematically miss information placed near the middle of the context. This post covers the Lost in the Middle phenomenon, the limits of NIAH methodology, alternative benchmarks, and the recall and empty-response patterns measured across four reasoning-effort modes.
The Lost in the Middle Effect
Liu et al. (2023) ran a series of multi-document question-answering experiments, placing the relevant document at varying positions within a long context window. The result was a consistent U-shaped performance curve: models recalled information at the beginning and end of the context well, but recall dropped substantially for content placed in the middle.
The practical implication is direct. A model that advertises a 128K context window does not uniformly use that window. Feeding a 50-page contract to such a model and asking it to find a clause buried on page 25 is a materially different task than asking it to find a clause on page 1 or page 50. The benchmark number says nothing about this.
The effect held across multiple model families in 2023, and subsequent work has found it persists in newer architectures — though the magnitude varies. Some models have improved middle-context recall through targeted fine-tuning, but the U-shape remains a baseline assumption worth testing rather than a solved problem.
NIAH Methodology, Examined
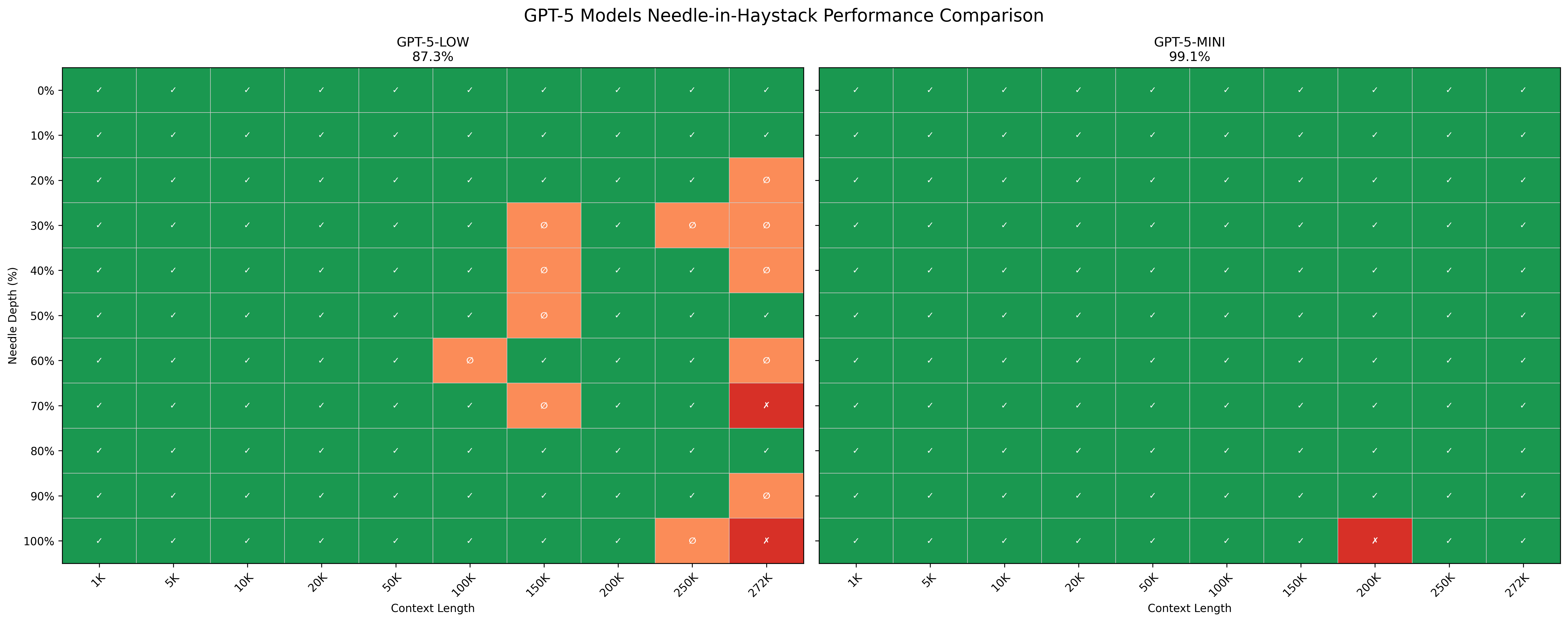
Kamradt's NIAH design is clean and reproducible. A short factual statement — the "needle" — is inserted at a specified depth into a long "haystack" of text. The model is asked a direct question whose answer requires recalling the needle. The test sweeps across a grid of context lengths and insertion depths, producing a heat map that visualizes where recall breaks down.
The standard grid covers multiple context lengths (from a few thousand tokens up to the model's claimed maximum) and insertion depths ranging from 0% (document start) to 100% (document end), usually at 10-percentage-point intervals. The judge evaluates whether key terms from the needle appear in the response. If they do, the test is marked as passed.
This produces readable results quickly, and the grid format makes it easy to spot whether failures cluster at long contexts, deep middles, or both. Those properties explain its adoption.
The limitations are just as structural. The needle is a synthetic insertion — a fact about San Francisco dropped into Genesis or Hamlet. The haystack text and the needle text come from entirely different domains, which means the needle stands out as contextually incongruent. A sufficiently capable model may detect this incongruence and treat the needle as suspect rather than as a reliable source. The test also probes single-fact retrieval only: one short sentence, one direct question, one binary pass/fail. Real long-context tasks more often require integrating multiple relevant passages, tracking state across a document, or answering questions where the relevant information is distributed rather than localized. Finally, the evaluator itself — the keyword-presence judge — can drift over time if the judge model is updated, making scores across different test runs harder to compare.


Alternative Benchmarks
RULER (Hsieh et al., 2024) was designed directly to address NIAH's single-fact, single-needle limitation. It extends the haystack framework to include multi-key tasks — multiple needles scattered across the document, with the question requiring the model to retrieve all of them. It also includes tasks that require aggregation across the context, not just retrieval of a single sentence. RULER scores are not directly comparable to raw NIAH scores, and models that perform well on NIAH do not automatically transfer those scores to RULER's multi-key variants.
LongBench (Bai et al., 2023) shifts the evaluation from synthetic insertion to naturally occurring long-document tasks. It covers summarization, multi-document QA, few-shot learning with long demonstrations, code completion, and reading comprehension across real documents in both English and Chinese. The trade-off is that individual tasks are harder to interpret in isolation — a score drop on LongBench's QA subset could come from factual recall failure, reasoning failure, or simply from the model producing answers that miss the reference phrasing. LongBench is closer to what production long-context applications actually require, which makes it useful as a complement to NIAH rather than a replacement.
NoCha (Karpinska et al., 2024) focuses on narrative coherence in book-length texts. The benchmark presents models with claims about a novel — some true, some subtly false — and asks the model to verify them against the full text. This tests something NIAH does not: whether a model can reason about character behavior, plot progression, and narrative consistency across hundreds of pages of dense prose. NoCha's pass rates for current models are low enough to be informative. It targets the kind of long-context reasoning that agentic workflows over large codebases or legal documents would require.
Each addresses a different gap in NIAH. Using one does not make the others redundant.
Case Study — Measured Results Across Four Reasoning-Effort Modes
Setup
The test used the following configuration:
- Needle: "The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day."
- Haystack: approximately 4.2M tokens of Old Testament text, Shakespeare plays, and the UN Declaration of Human Rights, combined into a corpus and truncated to the target context length for each trial
- Context lengths: 1K, 5K, 10K, 20K, 50K, 100K, 150K, 200K, 250K, and 272K tokens — 10 lengths
- Insertion depths: 0%, 10%, 20%, 30%, 40%, 50%, 60%, 70%, 80%, 90%, 100% — 11 positions
- Total trials per mode: 110 (10 lengths x 11 depths)
- Pass criterion: response contains both "sandwich" and "dolores park" (case-insensitive)
- Modes tested: mini, low, high, nano
Results Summary
| Mode | Pass rate | Passed / Total |
|---|---|---|
| mini | 96.4% | 106 / 110 |
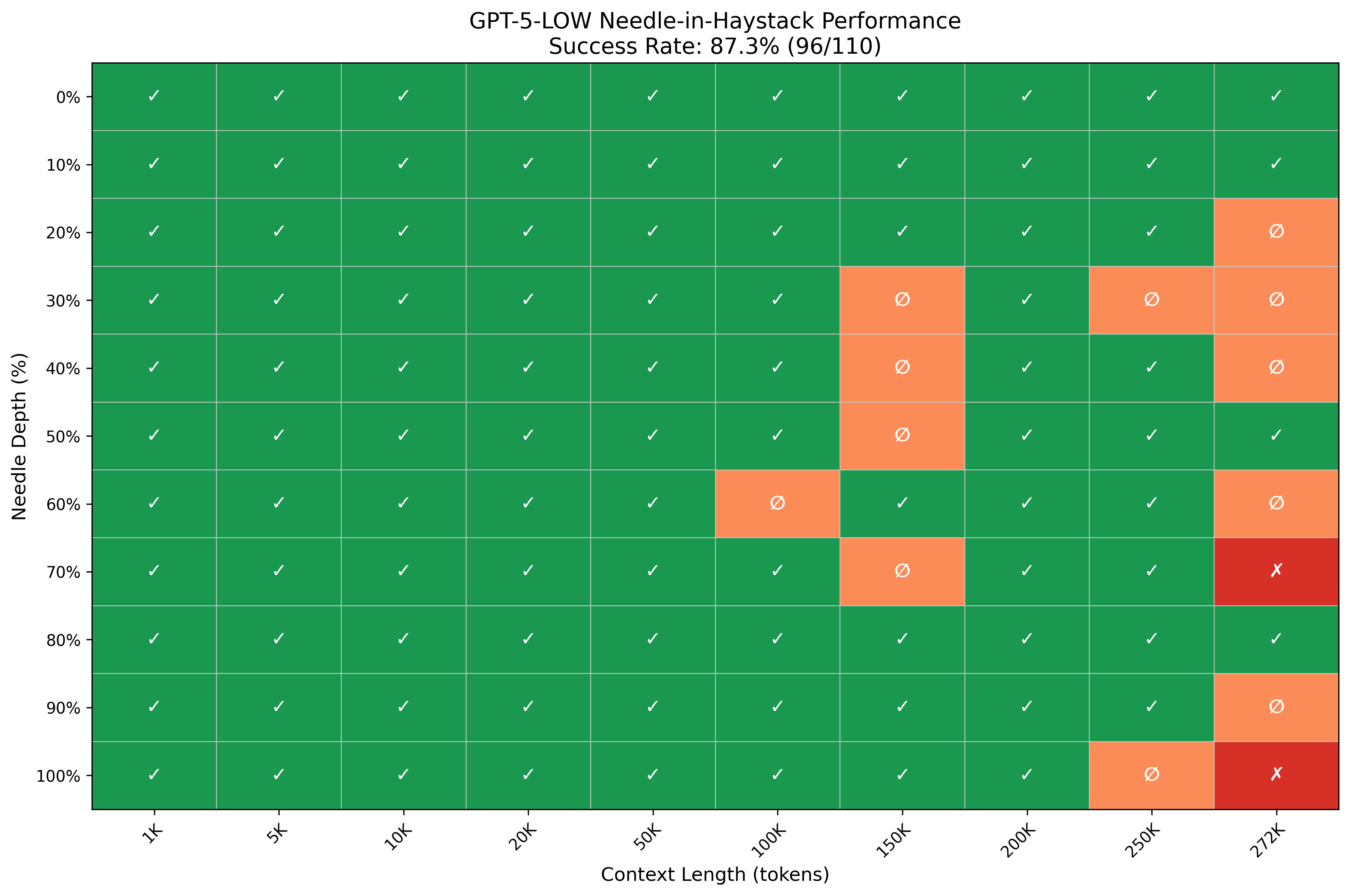
| low | 86.4% | 95 / 110 |
| high | 0% (empty responses throughout) | — |
| nano | 0% (empty responses throughout) | — |
Why Mini Scored Highest
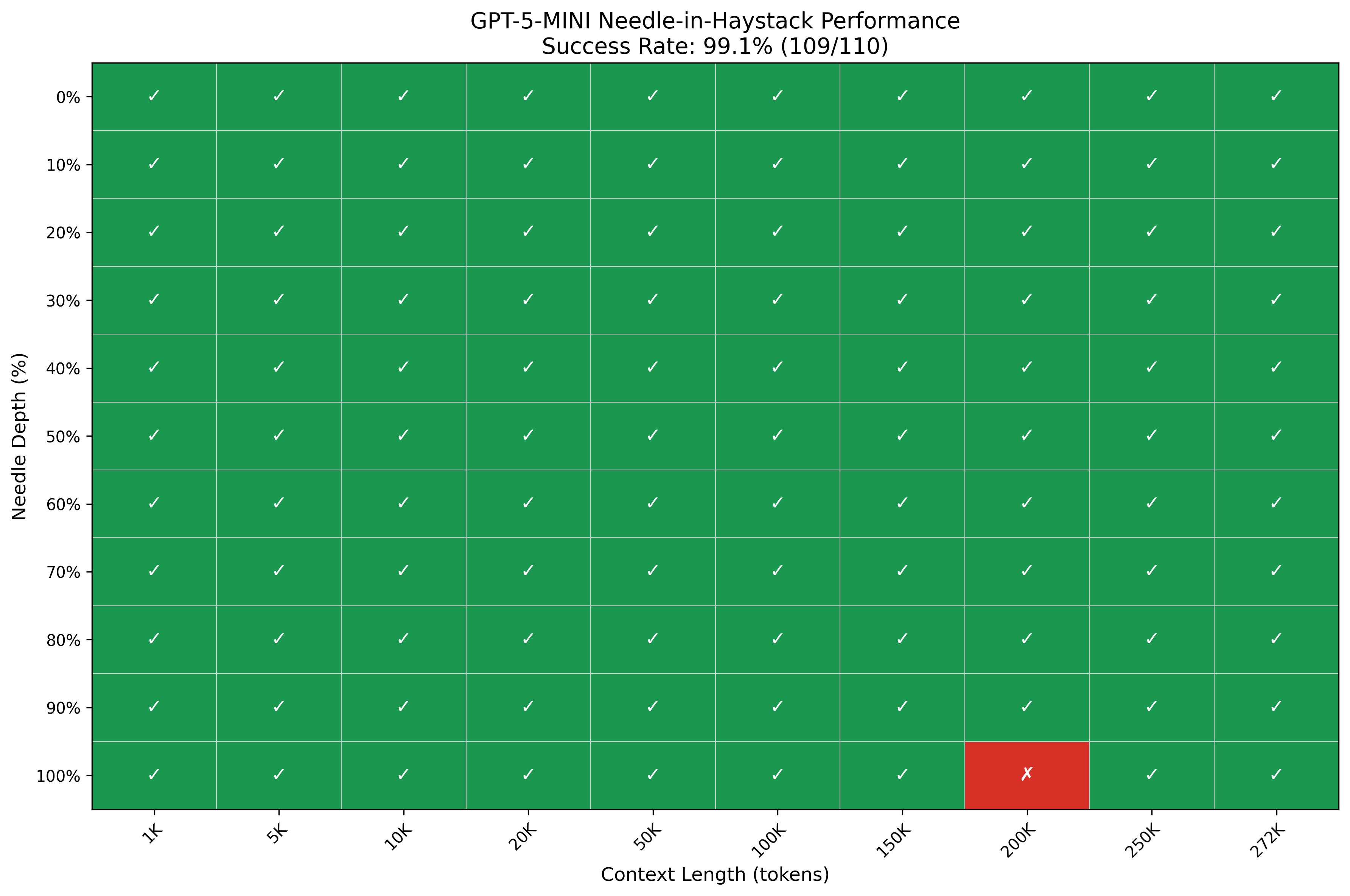
The mini mode's 96.4% pass rate with only 4 failures is the most straightforward result. Its failures were concentrated at the extreme end of the context range: one failure at 200K tokens at 100% depth, and three failures at 272K tokens at depths of 80%, 90%, and 100%. The pattern suggests mini processes the bulk of the context window reliably and begins to lose end-positioned content only at the longest lengths — a reasonable degradation profile.
The low mode's 86.4% is more sensitive to context length. Failures begin appearing at 100K tokens and become more frequent from 150K upward, with particular clustering at middle-depth positions (30–70%) in the 150K+ range. This matches the Lost in the Middle prediction: as context grows, middle positions become harder to retrieve. At 272K, the low mode also produced some empty responses alongside explicit statements that San Francisco was not mentioned in the document — a different failure mode than simple retrieval error.
Possible Explanations for High and Nano Empty Responses
The high and nano modes returned empty strings across the full length-and-depth grid. Several mechanisms could explain this, and the available data does not cleanly distinguish between them.
Context-authenticity detection. A model with stronger reasoning capacity may recognize that a San Francisco sandwich fact inserted into biblical genealogies is incongruent — the kind of synthetic artifact that a careful reader would flag. One interpretation is that the model's confidence in the needle is low enough that it declines to propagate the information, returning nothing rather than surfacing a suspect fact. The complication with this explanation is that the same insertion is equally incongruent at 1K tokens as at 272K, yet the pattern held uniformly across all lengths. If context incongruence were the only driver, shorter-context trials might be expected to pass occasionally.
Resource allocation at scale. High-reasoning modes involve more internal computation per token. At very long contexts, the allocated computation budget may not be sufficient for the model to complete processing, resulting in a truncated or empty output. This is consistent with empty-string responses rather than "I cannot find this" responses, which would require the model to have completed processing.
Confidence thresholds. Some model configurations apply stricter confidence requirements before outputting an answer. The hypothesis is that longer context introduces more competing signals, and the model's internal confidence in any single retrieved fact falls below the threshold required to produce a response. At shorter contexts, the same threshold might be satisfied.
API and implementation interaction. The interaction between high reasoning effort and the response generation pipeline — particularly the max_completion_tokens parameter set to 150 — may have produced edge-case behavior at scale. Reasoning-intensive modes may require more tokens to arrive at an answer, and a hard cap of 150 tokens may have cut off responses before they completed, producing empty strings.
These explanations are not mutually exclusive. The most likely account involves a combination of factors that reinforce each other at long context lengths with synthetic content.
The high and nano modes' failure on NIAH does not mean those modes are worse at long-context tasks in general. It means NIAH, as configured, did not measure what those modes do. A benchmark built around synthetic needle insertion may actively penalize models that evaluate source authenticity. That is a limitation of the benchmark, not a verdict on the model.
Evaluator Checklist
When evaluating a model for long-context use, the following categories are worth treating as separate questions rather than collapsing into a single aggregate score.
Synthetic versus natural needles. Test with content drawn from the same domain as the haystack, not inserted from an unrelated domain. A legal clause inserted into a legal document is a materially different test than a San Francisco fact inserted into Genesis. If only synthetic needles are used, the score reflects recall of incongruent insertions, not document-native retrieval.
Multi-hop recall. Single-fact retrieval is the easiest form of long-context task. Evaluation that stops there misses the tasks where long context matters most: synthesizing two facts from different locations, tracking a variable across a document, or answering a question that requires reading section A and section D together. Include at least one multi-hop task in any practical evaluation.
Empty responses and refusals as first-class results. A model that returns an empty string or declines to answer is not equivalent to a model that answers incorrectly. Both are failures, but they have different implications for production use. Report empty-response rates separately from recall rates. Omitting them from the aggregate inflates the apparent pass rate and hides a class of failure that may be systematic.
Full depth-by-length grid. Averages conceal position-dependent degradation. A model that scores 90% on average might score 60% at middle depths and 100% at endpoints. The heat map view is more informative than the summary number for predicting where failures will occur in real documents.
Evaluator drift. If the judge is an LLM (as is common in automated evaluation pipelines), check whether judge behavior has changed across model versions. A keyword-presence judge is immune to this specific drift, but semantic judges are not. For longitudinal comparisons, pin the judge version or use a deterministic evaluation criterion.
Closing
NIAH is a useful starting point for characterizing long-context behavior — its grid format surfaces position-dependent failures that aggregate scores hide, and it runs quickly. It can also fail in the opposite direction: reasoning-intensive modes that evaluate source authenticity before answering may return nothing at all. Treat NIAH scores as a first filter, not a final verdict. The checklist above covers the additional dimensions — multi-hop recall, empty-response rates, natural-domain needles, and evaluator consistency — that a NIAH score leaves unexamined. For any model being selected for production long-context work, those dimensions are worth testing explicitly.