긴 컨텍스트 평가의 진짜 질문 — NIAH와 Lost in the Middle
Needle-in-a-Haystack(NIAH)은 LLM의 긴 컨텍스트 활용 능력을 측정하는 표준 벤치마크입니다. 그러나 NIAH 점수가 곧 '긴 컨텍스트 활용 능력'을 의미하지는 않습니다. Liu et al. (2023)의 'Lost in the Middle' 연구는 모델이 컨텍스트 중간 위치의 정보를 체계적으로 누락한다는 U자형 곡선을 보고했습니다. 이 글에서는 Lost in the Middle 현상, NIAH 방법론의 한계, 대안 벤치마크, 그리고 GPT-5 reasoning effort 4모드의 실제 측정 결과를 정리합니다.
Lost in the Middle 현상
Liu et al. (2023)은 여러 LLM에 20개의 문서를 제공하고, 정답이 담긴 문서의 위치를 바꿔가며 다중문서 질의응답 성능을 측정했습니다. 결과는 일관된 U자형 곡선을 보였습니다. 컨텍스트 앞부분이나 끝부분에 정답 문서가 있을 때는 정확도가 높았고, 중간에 위치할수록 크게 떨어졌습니다.
이 현상은 단순히 모델 크기나 컨텍스트 창 크기와 무관합니다. 같은 컨텍스트 창을 가진 모델이라도 중간 위치 정보를 회상하는 능력은 상당히 다를 수 있습니다. 특히 주목할 점은 컨텍스트 창이 커질수록 이 U자형 곡선이 더 두드러진다는 사실입니다. 긴 컨텍스트를 지원한다는 사실이 중간 위치 정보를 잘 쓴다는 보장이 아닙니다.
실용적으로는, RAG 파이프라인에서 검색된 문서를 어떤 순서로 프롬프트에 담는지가 성능에 직접 영향을 준다는 의미이기도 합니다. 관련성이 높은 문서를 중간에 배치하면 같은 정보라도 모델이 덜 활용하게 됩니다.
NIAH 방법론 해부
NIAH는 Greg Kamradt가 설계한 벤치마크로, 긴 텍스트(haystack) 안에 단일 사실 문장(needle)을 삽입하고 모델이 이를 회상할 수 있는지를 측정합니다. 평가 축은 두 가지입니다. 컨텍스트 길이(얼마나 긴 텍스트인지)와 삽입 깊이(needle이 문서의 몇 % 지점에 있는지)로 구성된 2D 그리드를 만들고, 각 셀의 성공률을 히트맵으로 시각화합니다.
방법론 자체는 명확하고 재현성이 높습니다. 그러나 설계 방식에서 비롯되는 구조적 한계가 있습니다.
합성 삽입으로 인한 맥락 부조화. haystack은 대개 특정 주제의 텍스트(소설, 성경, 학술 논문 등)로 구성됩니다. 여기에 맥락과 전혀 관계없는 사실 문장을 끼워 넣으면, 원래 텍스트와 needle 사이에 의미적 단절이 생깁니다. 모델이 이 단절을 감지하면 결과가 달라질 수 있습니다.
단일 사실 편향. NIAH는 "샌프란시스코에서 가장 좋은 것은 샌드위치를 먹고 Dolores Park에 앉아 있는 것이다" 같은 단일 사실의 회상을 측정합니다. 실제 긴 컨텍스트 활용은 여러 문서에 걸쳐 정보를 통합하거나 다단계 추론을 요구하는 경우가 더 많습니다. 단일 사실 회상 능력과 실제 활용 능력은 다른 문제입니다.
평가자 드리프트. judge 모델이나 규칙 기반 평가 기준을 쓸 때, 시간이 지나거나 컨텍스트 길이가 달라지면 점수 분포가 조금씩 바뀔 수 있습니다. 긴 컨텍스트에서 judge 자체도 같은 '중간 회상' 문제를 겪을 가능성이 있습니다.
NIAH 점수가 높다는 것은 "특정 조건에서 단일 사실을 회상할 수 있다"는 뜻이지, 긴 컨텍스트를 전반적으로 잘 활용한다는 뜻이 아닙니다.


대안 벤치마크
NIAH의 한계를 보완하기 위해 여러 벤치마크가 제안되었습니다.
RULER는 NIAH를 확장한 벤치마크로, 단일 needle 회상에서 벗어나 다중 needle, needle 관계 추론, 긴 컨텍스트 요약 등 더 다양한 작업을 포함합니다. 합성 데이터 기반이라는 점은 같지만, 작업 다양성을 높여 단일 사실 편향을 줄이려는 시도입니다. 컨텍스트 길이별로 정규화된 점수를 제공해 모델 간 비교가 용이합니다.
LongBench는 실제 사용 사례에서 추출한 자연 언어 태스크로 구성됩니다. 다중문서 질의응답, 코드 완성, 요약 등 6개 범주의 태스크를 포함하며, 영어와 중국어 이중언어 버전이 있습니다. 합성 삽입 방식을 쓰지 않기 때문에 맥락 부조화 문제가 없고, 실제 업무 능력과의 상관관계가 NIAH보다 높습니다.
**NoCha(Novel Challenges)**는 긴 소설 텍스트를 대상으로 사실 확인 과제를 수행합니다. 소설 전체를 읽어야 판별할 수 있는 참/거짓 문장을 제시하고, 단순 검색으로는 해결이 불가능한 multi-hop 회상과 서사 이해를 요구합니다. NIAH가 측정하지 못하는 "이해"와 "추론" 영역을 타겟으로 합니다.
세 벤치마크 모두 NIAH와 병행할 때 더 의미 있는 그림이 나옵니다.
케이스 스터디 — GPT-5 reasoning effort 4모드 측정
테스트 설정
needle은 단일 문장입니다.
"The best thing to do in San Francisco is eat a sandwich and sit in Dolores Park on a sunny day."
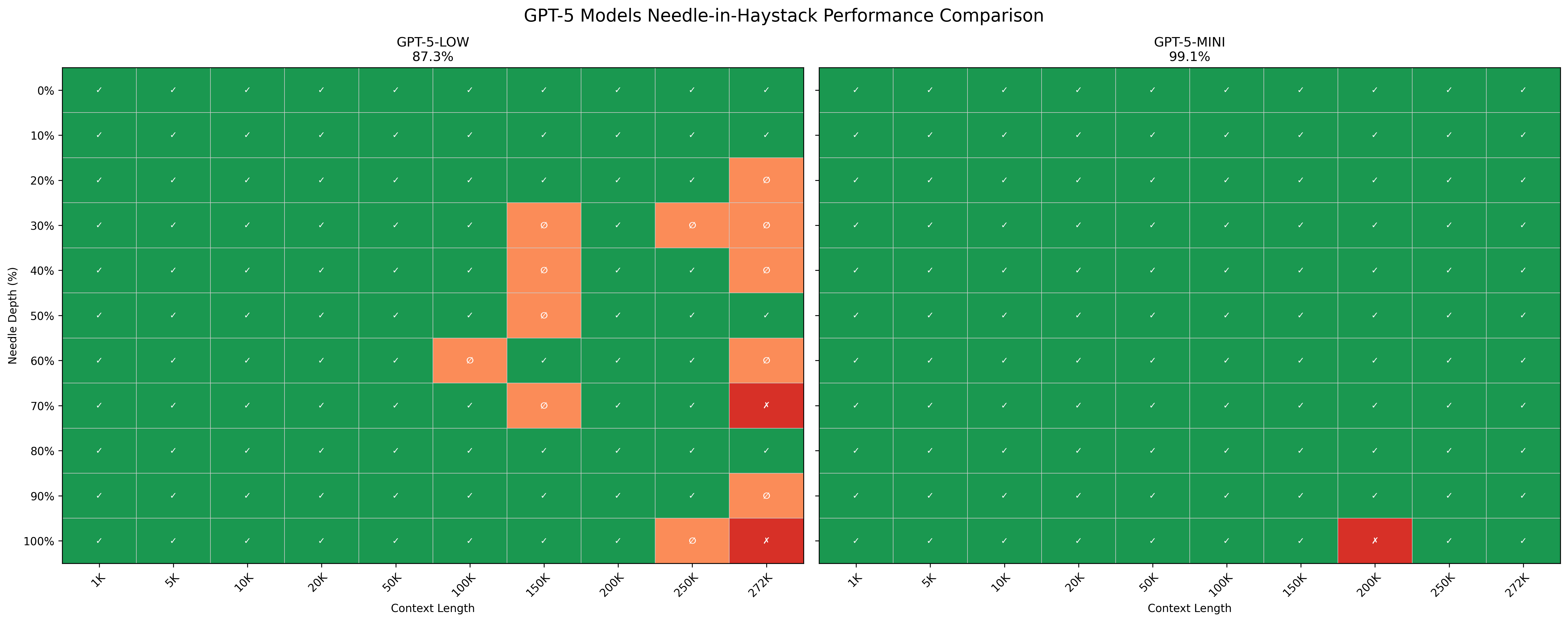
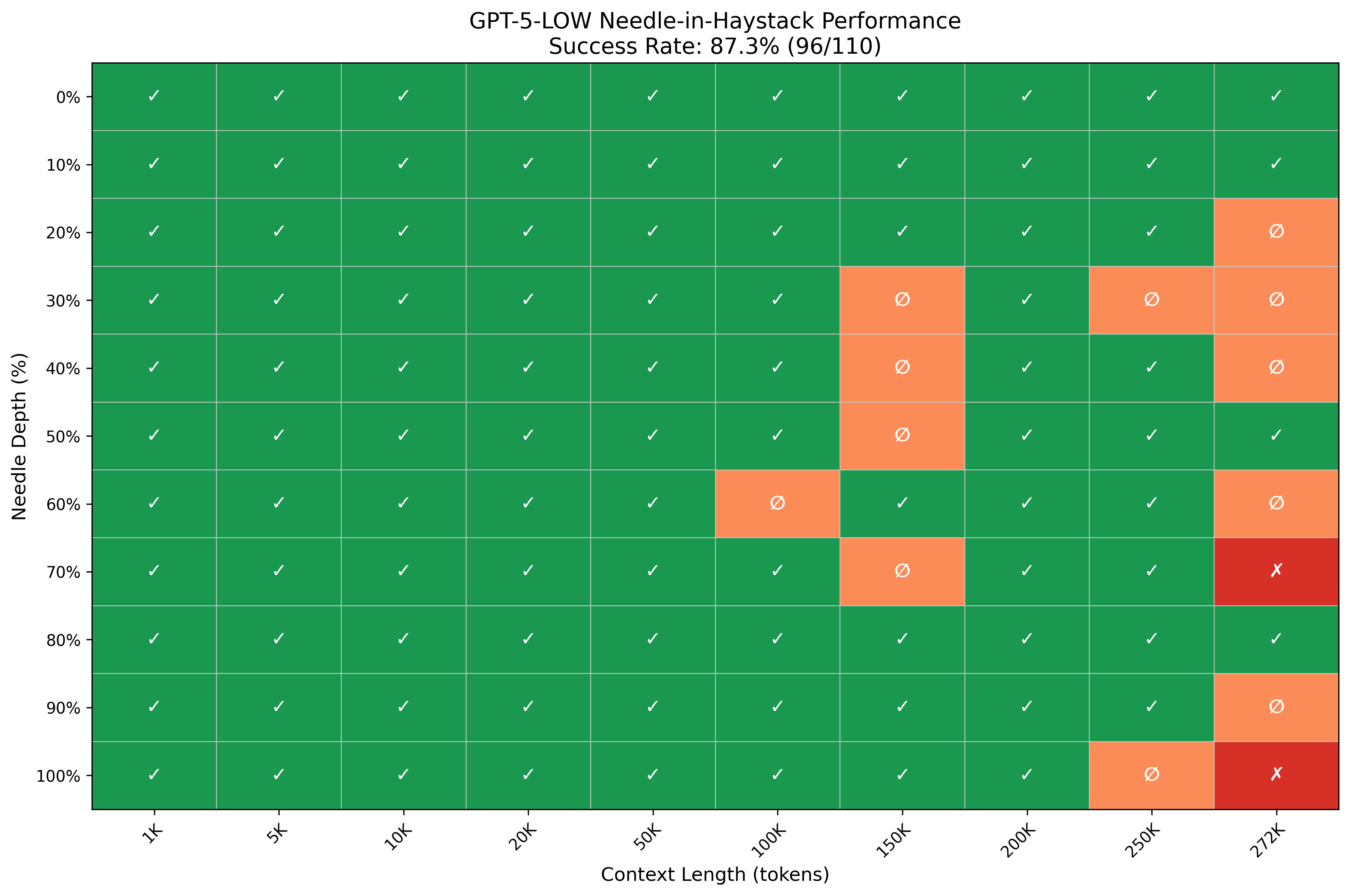
haystack은 성경(구약), 셰익스피어 작품(햄릿, 로미오와 줄리엣 등), UN 세계인권선언문 등을 포함한 약 4.2M 토큰 규모의 공개 텍스트 코퍼스입니다. 컨텍스트 길이는 1K에서 272K 토큰까지 10개 구간(1K, 5K, 10K, 20K, 50K, 100K, 150K, 200K, 250K, 272K), 삽입 깊이는 0%에서 100%까지 11개 위치(0%, 10%, ..., 100%)를 사용했습니다. 조합당 한 번씩 측정하면 총 110개 셀이 됩니다.
판정 기준은 응답에 "sandwich"와 "dolores park" 두 키워드가 모두 포함되어 있을 때 성공입니다.
결과
| 모드 | 성공률 | 성공 건수 |
|---|---|---|
| GPT-5-mini | 96.4% | 106/110 |
| GPT-5-low | 86.4% | 95/110 |
| GPT-5-high | 0% | 빈 응답 |
| GPT-5-nano | 0% | 빈 응답 |
GPT-5-mini는 200K 토큰 @ 100% 깊이, 272K 토큰 @ 80%·90%·100% 깊이에서만 실패했습니다. 측정 범위 안에서는 대체로 안정적입니다. GPT-5-low는 100K 토큰을 넘어서면서 간헐적으로 실패하기 시작하고, 150K 이상의 컨텍스트에서 중간 깊이(30~70%) 회상이 특히 불안정했습니다. 272K에서는 빈 응답과 "문서에 샌프란시스코가 언급되지 않았다"는 명시적 거부가 각각 한 건씩 발생했습니다.
mini가 가장 높은 이유
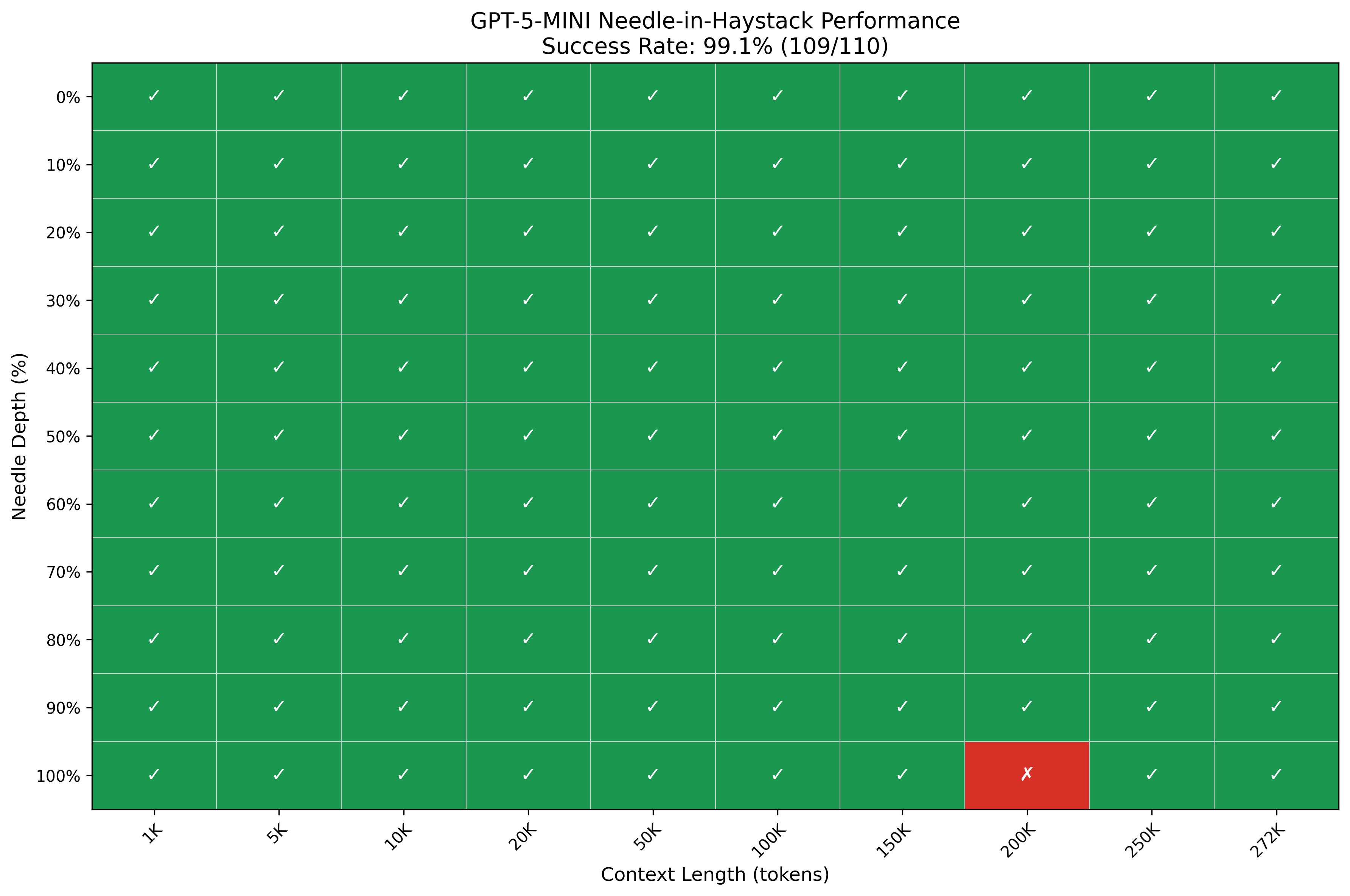
직관적으로 reasoning effort가 낮을수록 단순 텍스트 매칭에 가까운 동작을 합니다. NIAH는 본질적으로 특정 문자열이 응답에 포함되는지를 확인하는 평가입니다. 정교한 추론보다 신속한 회상에 최적화된 모드가 이 과제에서 유리할 수 있습니다. 이는 NIAH의 한계를 역으로 드러내는 결과이기도 합니다. 더 '똑똑한' 모드가 더 낮은 점수를 받았기 때문입니다.
high와 nano의 빈 응답
high와 nano가 110개 셀 전부에서 빈 응답을 반환한 원인은 단정하기 어렵습니다. 현재로서 가능한 설명은 다음과 같습니다.
haystack을 구성하는 성경 텍스트 한가운데에 샌프란시스코 사실이 삽입된 상황은 의미적으로 명백한 부조화입니다. 추론 능력이 높은 모드는 이 부조화를 감지하고 해당 정보의 진위를 의심하는 방향으로 동작할 수 있습니다. 다만 이 이론은 한 가지를 설명하지 못합니다. 1K~10K 토큰처럼 짧은 컨텍스트에서도 needle이 성경 텍스트 안에 삽입된다는 점은 동일한데, 짧은 컨텍스트에서 성공 사례가 있었는지는 측정 결과에 명시되어 있지 않습니다.
추론 노력이 높을수록 긴 컨텍스트를 처리하는 데 더 많은 자원을 소비하는 것도 관련이 있을 수 있습니다. 자원 할당 한계에 도달하면 응답 생성 자체가 완료되지 못할 수 있습니다. 또한 컨텍스트가 길어질수록 모델이 응답하기 위해 요구하는 내부 신뢰도 임계값이 높아진다면, 불확실성이 클 때 침묵을 택하는 동작으로 해석할 수도 있습니다. API 수준에서 reasoning effort 파라미터와 응답 생성 로직의 상호작용이 특정 조건에서 빈 응답을 유발할 가능성도 배제하기 어렵습니다.
어느 설명이 맞든, 결론은 하나입니다. NIAH에서 빈 응답은 "실패"로 집계되지만, 그것이 모델의 긴 컨텍스트 이해 능력 부재를 의미하는지는 별개의 질문입니다.
평가자 체크리스트
긴 컨텍스트 모델을 평가할 때 고려할 사항입니다.
합성 needle에만 의존하지 않습니다. 맥락과 어울리는 자연스러운 needle을 사용하면 합성 삽입 특유의 부조화 감지 효과를 제거할 수 있습니다. 평가 목적이 실제 사용 시나리오에 가까울수록 needle도 그에 맞게 설계해야 합니다.
단일 사실을 넘어 multi-hop 회상을 측정합니다. 단일 사실 회상 능력과 여러 위치의 정보를 통합하는 능력은 다릅니다. 실제 사용 사례에서는 후자가 더 중요한 경우가 많습니다.
빈 응답과 거부를 별도 카테고리로 기록합니다. 빈 응답을 단순히 실패율에 합산하면 실패 원인이 뭉개집니다. 회상 실패인지, 진위 판단에 의한 침묵인지, 처리 한계인지를 구분하는 것이 후속 대응에 도움이 됩니다.
depth × length 전체 그리드를 확인합니다. 평균 성공률만 보면 컨텍스트 길이별, 깊이별 분포가 숨겨집니다. 어떤 모델은 짧은 컨텍스트에서 강하지만 길어질수록 중간 위치 회상 성공률이 급락하는 패턴을 보입니다. 히트맵 전체를 보지 않으면 이런 패턴이 안 보입니다.
evaluator drift를 점검합니다. judge 모델 기반 평가를 쓴다면, 시간에 따라 judge가 교체되거나 버전이 올라갈 때 점수 분포가 달라질 수 있습니다. 동일 셀을 다른 시점에 재측정해 일관성을 확인합니다.
마무리
NIAH는 긴 컨텍스트 평가의 시작점이지 종착점이 아닙니다. 96.4%라는 수치는 "이 모드가 110개 셀 중 106개에서 needle 키워드를 응답에 포함했다"는 사실을 말해줍니다. 그 이상도 이하도 아닙니다. 모델이 긴 컨텍스트에서 실제로 무엇을 할 수 있는지를 알고 싶다면 RULER, LongBench, NoCha 같은 보완 벤치마크를 함께 써야 하고, 무엇보다 자신의 사용 사례에 맞는 평가 기준을 직접 설계하는 것이 가장 신뢰할 수 있는 방법입니다.
참고 자료
- Liu, N. F., Lin, K., Hewitt, J., Paranjape, A., Bevilacqua, M., Petroni, F., & Liang, P. (2023). Lost in the Middle: How Language Models Use Long Contexts. arXiv:2307.03172
- Kamradt, G. (2023). LLMTest_NeedleInAHaystack. GitHub.
- Hsieh, C.-Y., Chen, S.-A., Li, C.-L., Kasner, Z., Lee, C., Wan, X., ... & Pfister, T. (2024). RULER: What's the Real Context Size of Your Long-Context Language Models? arXiv:2404.06654
- Bai, Y., Lv, X., Zhang, J., Lyu, H., Tang, J., Huang, Z., ... & Hou, L. (2023). LongBench: A Bilingual, Multitask Benchmark for Long Context Understanding. arXiv:2308.14508
- Karpinska, M., Thai, K., Indig, B., Meister, N., & Iyyer, M. (2024). One Thousand and One Pairs: A "Novel" Challenge for Long-Context Language Models. arXiv:2406.16264