Replacing Elasticsearch with PostgreSQL
Can PostgreSQL alone replace Elasticsearch for Korean search? I measured it end-to-end across eight phases — from morphological analyzers to hybrid retrieval.
The short answer: yes.
textsearch_ko (MeCab) + pg_textsearch BM25 + pgvector HNSW + DB-side RRF
→ MIRACL NDCG 0.77 @1.79ms / EZIS NDCG 0.86 @0.92msQuality matches Elasticsearch, and single-node latency is 2–5× faster. Vector-first systems like Qdrant and Vespa fall structurally behind on Korean text search.
Why this experiment
Korean search is not English search.
Stemming "running" to "run" in English is a handful of rules. Reducing "먹었다" to "먹-" in Korean requires a morphological analyzer. Without one, you cannot link "먹는", "먹고", "먹었던" to the same document, and BM25 quality collapses.
Elasticsearch ships with nori, a Korean morphological analyzer, and solves this out of the box. PostgreSQL's stock full-text search does not support Korean. So "Korean search = Elasticsearch" became the default.
Does it have to be?
The textsearch_ko extension plugs MeCab morphology into tsvector. pg_textsearch adds BM25 scoring. Add pgvector for dense retrieval, fuse BM25 and dense in a single SQL CTE with RRF, and you have a full hybrid pipeline inside PostgreSQL.
The question was whether this assembly actually holds up. "An extension exists" is not the same as "production quality". I measured across eight phases.
What I learned
The tokenizer decides everything
Most of Korean BM25 quality is explained by the tokenizer alone. Phase 1 compared MeCab, Kiwi, and Okt; MeCab won on the throughput-quality tradeoff and became the default for every later phase.
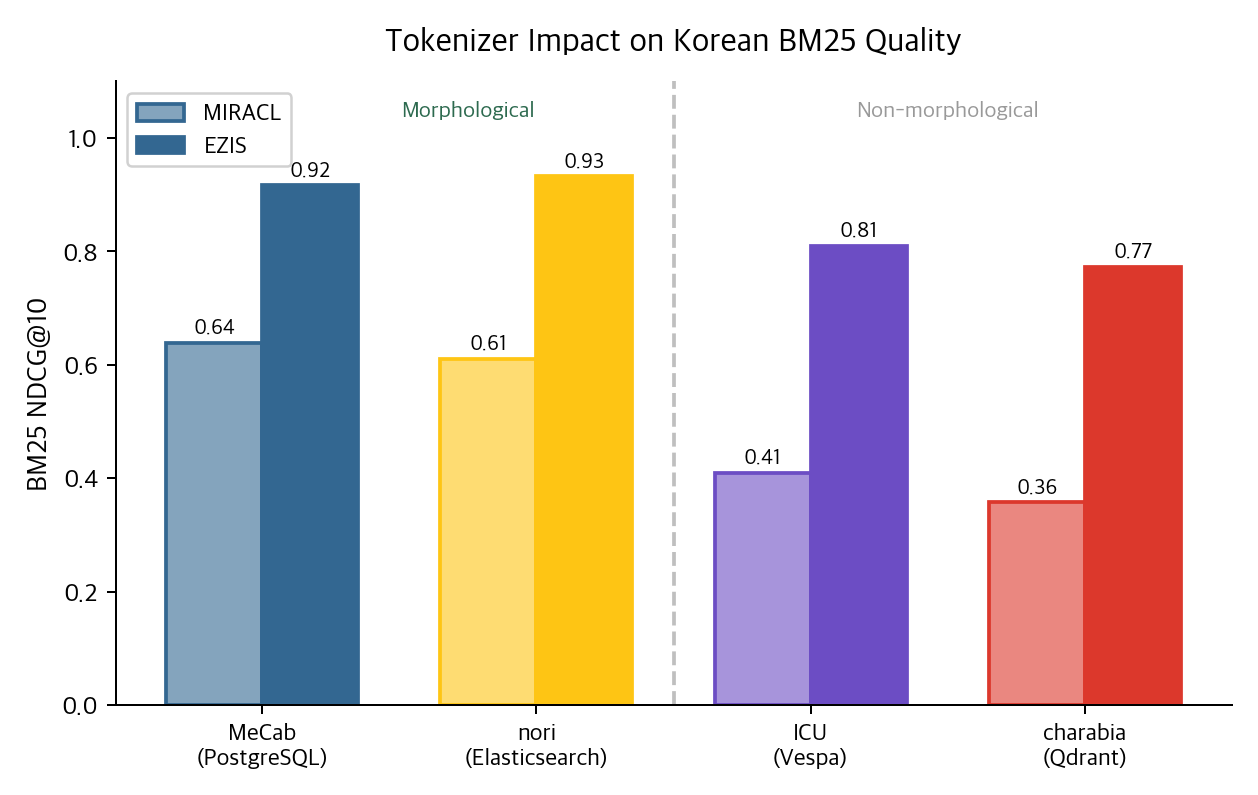
Systems with morphological analysis (PostgreSQL + MeCab, Elasticsearch + nori) hit NDCG 0.61–0.64 on MIRACL BM25. Vespa, which only does ICU Unicode word-boundary splitting, gets 0.41. Qdrant's multilingual tokenizer — Meilisearch's charabia under the hood, also Unicode-only — gets 0.36.
Without morphology, "데이터베이스" and "데이터" never link. "검색했다" and "검색" become separate tokens. No amount of BM25 tuning rescues a wrong tokenization.
One unexpected finding: nori works well under OR matching (NDCG 0.61) but collapses to 0.13 under AND matching. decompound_mode: mixed over-decomposes compounds, and AND retrieval requires every token to be present, so recall caves. PostgreSQL's textsearch_ko held 0.64 under the same AND condition.
The optimal method flips by domain
Running two datasets with opposite characters in parallel was the most important design choice in the study.
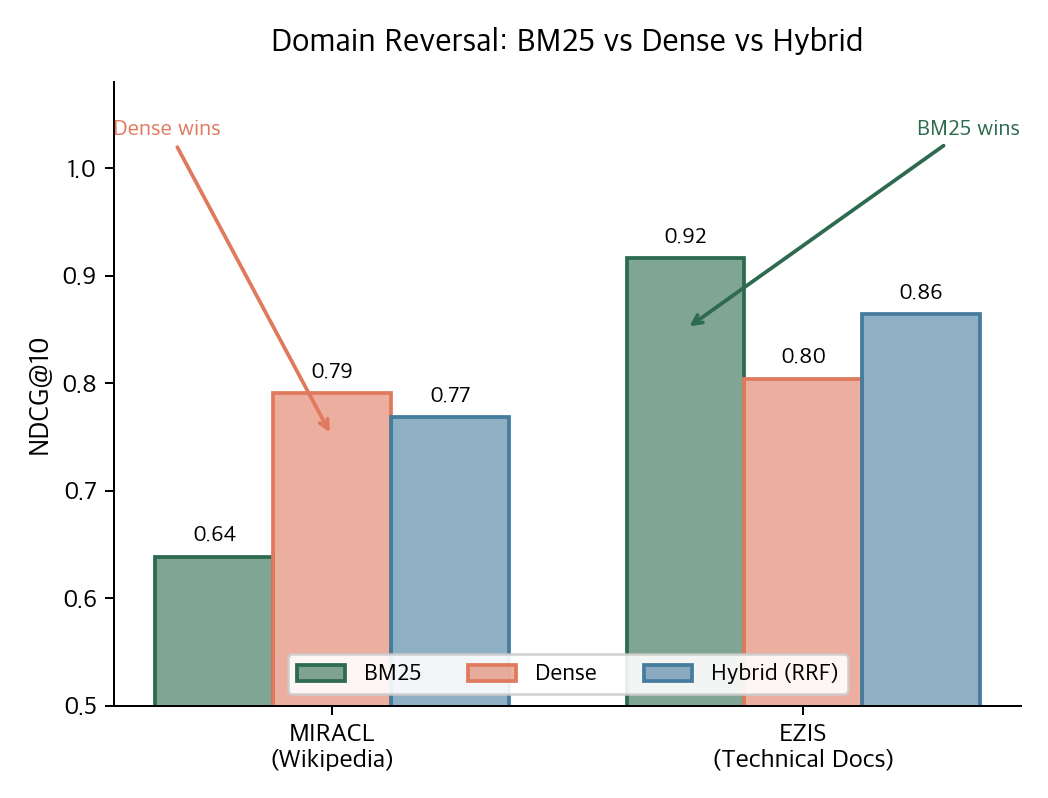
On MIRACL (Korean Wikipedia), dense retrieval (0.79) clearly beats BM25 (0.64). Semantic similarity matters more than keyword overlap.
On EZIS (Oracle DB manuals), BM25 (0.92) crushes dense (0.80). Exact-term matches like "ORA-01555" or "DBMS_STATS" matter more than semantic proximity.
The same PostgreSQL stack with the same hybrid configuration produces opposite winners depending on the data. There is no universally best method. Hybrid (RRF) is the safe default precisely because it hedges across this flip.
PostgreSQL is not slower than dedicated engines
Intuitively a specialized engine should outpace a general-purpose database. The numbers say otherwise.
PostgreSQL's DB-side RRF runs BM25 and dense queries inside a single SQL CTE and merges the results. One round trip between the app and the database. ES and Qdrant go through HTTP/JSON. That network overhead can dwarf the query itself.
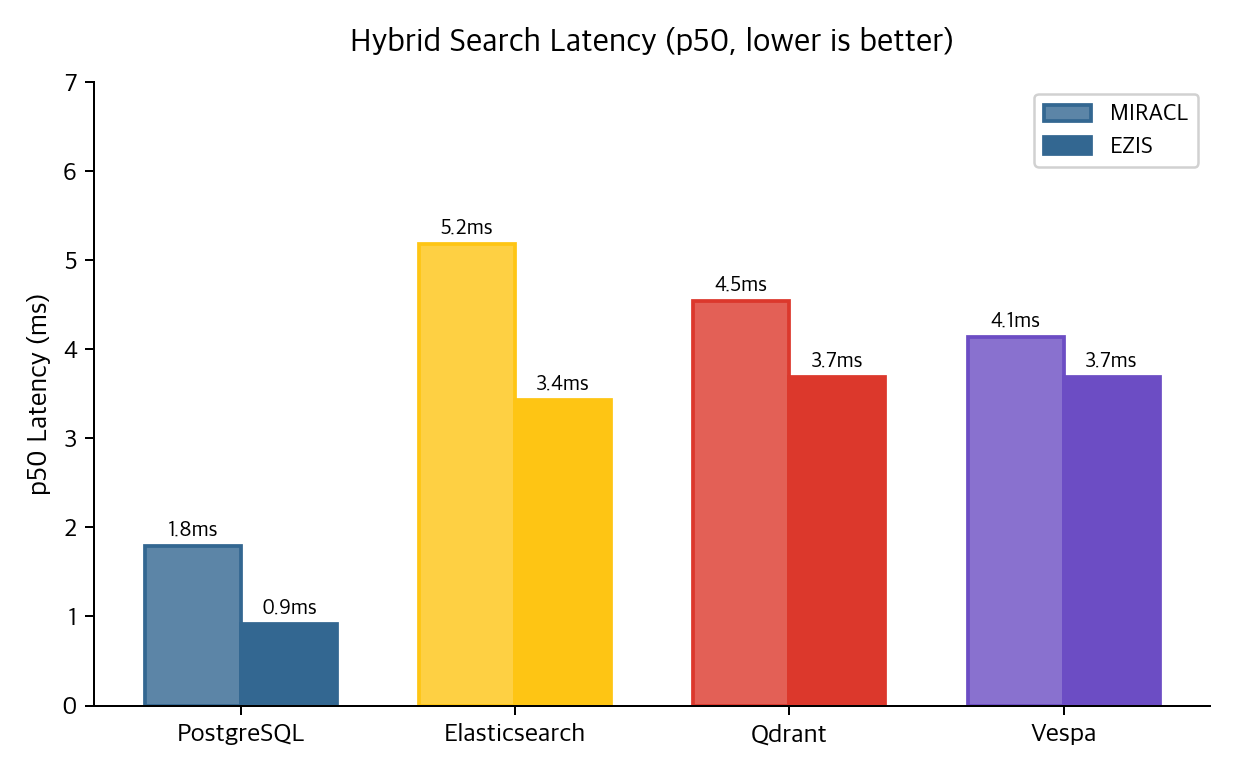
On MIRACL 10K: PostgreSQL RRF p50 = 1.79ms, ES = 5.18ms, Qdrant = 4.54ms, Vespa = 4.14ms. Single-node, warm-cache, retrieval-only — caveats noted. BGE-M3 embedding inference (~200ms) is excluded; query embeddings were precomputed.
Quality holds up too
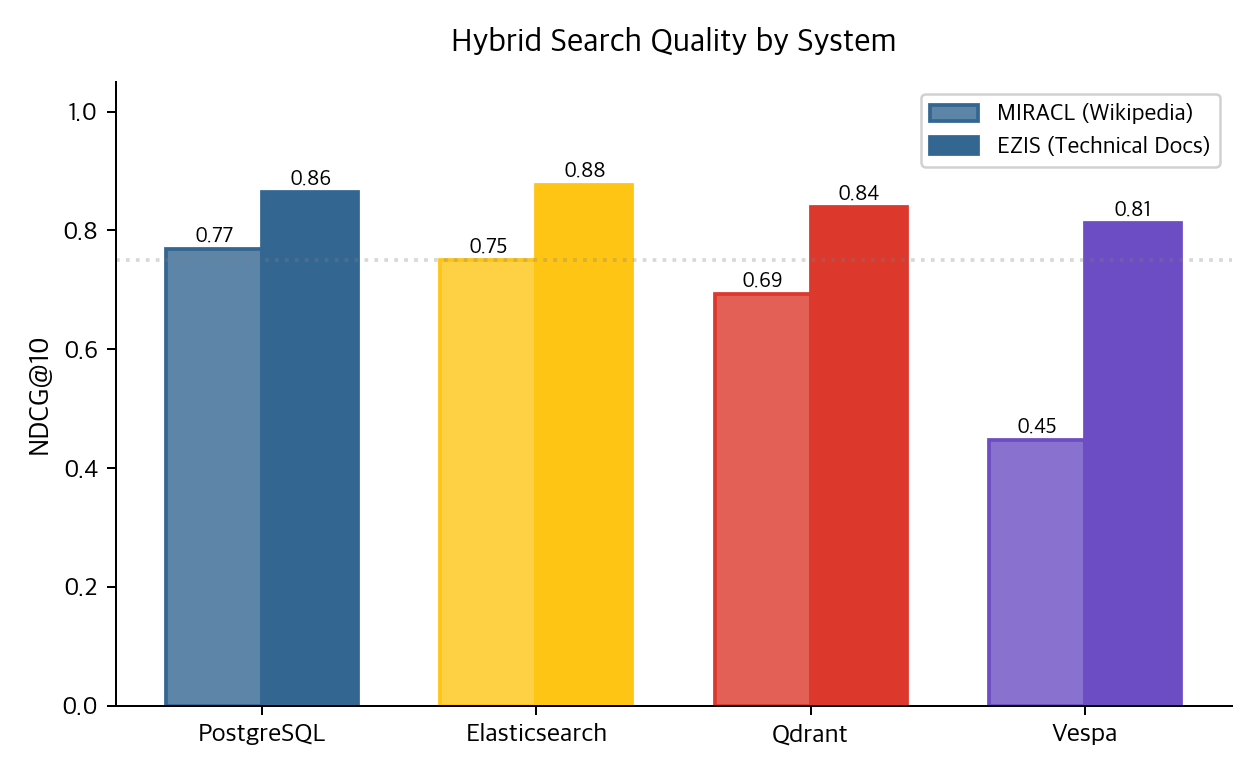
On MIRACL Hybrid, PostgreSQL (0.77) edges out Elasticsearch (0.75). On EZIS, ES (0.88) slightly beats PG (0.86), but I did not test statistical significance. Qdrant (0.69 / 0.84) and Vespa (0.45 / 0.81) bleed from their weak BM25 legs.
The key point: hybrid quality is bounded by BM25 quality. A weak BM25 leg makes hybrid worse than dense alone. Vespa's MIRACL hybrid (0.45) underperforming its dense-only number (0.79) is the proof.
Qdrant has no self-hosted BM25
Qdrant is structurally the strongest of the vector-first engines — quantization, filtering, multi-tenancy, distributed scale are all best-in-class. But its Korean text story is weak.
qdrant/bm25 exists as a server-side model, but it's Qdrant Cloud only. Self-hosted has no equivalent. The built-in TextIndexParams multilingual tokenizer is charabia from Meilisearch — Unicode word-boundary splitting, not morphology. So "먹었다" and "먹는" stay disconnected. Tokenizing externally with MeCab and ingesting as sparse vectors works but is TF × IDF, not true BM25 — no document-length normalization (k1, b), and NDCG sits at 0.36.
Vespa does not ship Korean morphology
Vespa expresses BM25 + ANN hybrid declaratively, very cleanly. But the default tokenizer is ICU, which does not do Korean morphology.
I tried three integration paths. (1) Lucene Linguistics with Nori — lucene-analysis-nori is not bundled, OSGi isolation blocks loading. (2) A custom Linguistics component (vespa-kuromoji-linguistics pattern) — the Java component loads, but the content node (proton, in C++) keeps using its own ICU tokenizer at index time, producing index/query token mismatch. (3) set_language — meaningless without Nori in Lucene Linguistics. Unlike PostgreSQL or Elasticsearch, Vespa's custom tokenizer does not apply consistently across indexing and query.
ICU BM25 generated enough noise that 0.1*bm25 + closeness linear fusion produced 0.45 — worse than dense-only (0.79).
Headline numbers
Cross-system (Phase 8)
| System | MIRACL Hybrid | EZIS Hybrid | p50 |
|---|---|---|---|
| PostgreSQL (RRF) | 0.7683 | 0.8641 | 1.79ms |
| ES 8.17 (nori, retriever.rrf) | 0.7501 | 0.8769 | 5.18ms |
| Qdrant 1.15 (MeCab sparse + dense) | 0.6924 | 0.8394 | 4.54ms |
| Vespa (ICU + HNSW) | 0.4463 | 0.8125 | 4.14ms |
Inside PostgreSQL (Phase 7)
| Method | MIRACL NDCG@10 | EZIS NDCG@10 | p50 |
|---|---|---|---|
| pg_textsearch BM25 (MeCab) | 0.6385 | 0.9162 | 0.44ms |
| Dense (BGE-M3 HNSW) | 0.7904 | 0.8041 | 1.2ms |
| RRF hybrid (DB-side) | 0.7683 | 0.8641 | 1.79ms |
| Bayesian hybrid (DB-side) | 0.7272 | 0.9249 | 9.55ms |
BM25 scaling (Phase 6–7)
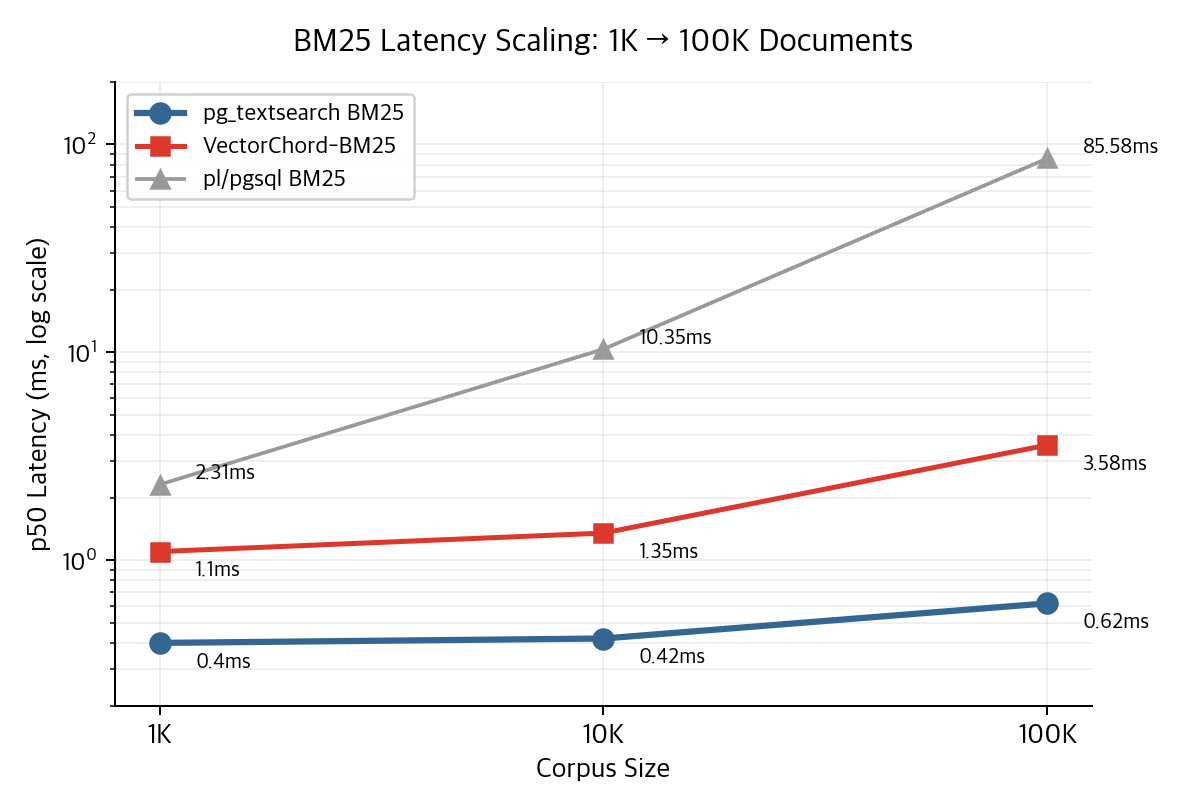
pg_textsearch holds 0.62ms at 100K documents. The hand-rolled pl/pgsql implementation blows up to 85ms. Index size is 18MB vs 501MB — a 27× gap.
Datasets
| Dataset | Character | Queries | Corpus | Bias |
|---|---|---|---|---|
| MIRACL-ko | General Wikipedia | 213 | 10K | Dense-favored |
| EZIS Oracle Manual | Technical reference | ~120 | ~200 | BM25-favored |
Running two opposite-character datasets in parallel was the design choice that kept the study honest — it prevents the illusion that any single method is universally best.
Phases
| Phase | What | Key finding |
|---|---|---|
| 0 | Prepare MIRACL-ko + EZIS | — |
| 1 | Compare analyzers (MeCab vs Kiwi vs Okt) | Kiwi-CoNg wins on quality, MeCab on speed → MeCab chosen for throughput/stability |
| 2 | Wire Korean morphology into tsvector |
textsearch_ko connects MeCab → tsvector |
| 3 | Compare in-PG BM25 implementations | pl/pgsql and pg_textsearch are the two viable options |
| 4 | BM25 vs neural (Dense, SPLADE) | Domain flips winner, hybrid is the safe default |
| 5 | Production hardening (incremental, concurrency) | pl/pgsql v2 + BGE-M3 confirmed |
| 6 | VectorChord-BM25 scaling (1K/10K/100K) | VectorChord is 24× faster than pl/pgsql |
| 7 | pg_textsearch hybrid (RRF, Bayesian) | pg_textsearch fastest at every scale, RRF chosen |
| 8 | Cross-system comparison (ES / Qdrant / Vespa) | PG stack matches on quality, 2–5× latency win |
Caveats
- All latencies are single-node, warm-cache, retrieval-only.
- Dense latency excludes BGE-M3 embedding inference (~200ms).
- PG numbers reuse Phase 7 measurements; this is cross-phase, not same-time head-to-head.
- BM25 query semantics differ across systems: PG uses AND, ES uses OR, Vespa uses weakAnd.
- No bootstrap CI or p-value testing for statistical significance.
So what should you use?
For a new project, starting with PostgreSQL alone is the rational default. Tokenizer, BM25, vectors, and hybrid fusion all live inside one transaction, one node, one backup, one permission model. Index-source sync and data-consistency issues disappear.
If you already run Elasticsearch and don't depend on nori AND matching, there's no reason to migrate. Korean quality is on par with PG under nori's OR semantics. The single-node latency win and operational simplicity are real, but not migration-forcing.
Qdrant and Vespa are not the first choice for Korean text search. They are vector-first systems where Korean BM25 has to be bolted on from the outside.
All code and per-phase analysis is published at github.com/ysys143/textsearch.