PostgreSQL로 Elasticsearch 대체하기
PostgreSQL만으로 Elasticsearch를 대체할 수 있을까? 형태소 분석기부터 하이브리드 검색까지, 8단계 실험으로 직접 측정했다.
결론부터 말하면, 된다.
textsearch_ko (MeCab) + pg_textsearch BM25 + pgvector HNSW + DB-side RRF
→ MIRACL NDCG 0.77 @1.79ms / EZIS NDCG 0.86 @0.92msElasticsearch와 품질이 동등하고, 단일 노드 기준 latency는 2~5배 빠르다. Qdrant, Vespa 같은 벡터 전용 DB들은 한국어 텍스트 검색에서 구조적으로 밀린다.
왜 이 실험을 했나
한국어 검색은 영어와 다르다.
영어에서 "running"을 "run"으로 줄이는 스테밍은 규칙 몇 개면 된다. 한국어에서 "먹었다"를 "먹-"으로 분리하려면 형태소 분석기가 필요하다. 이게 없으면 "먹는", "먹고", "먹었던"을 같은 문서로 연결할 수 없고, BM25 검색 품질이 반토막 난다.
Elasticsearch는 nori라는 한국어 형태소 분석기를 내장하고 있어서 이 문제를 바로 해결해준다. PostgreSQL 기본 full-text search는 한국어를 지원하지 않는다. 그래서 보통 "한국어 검색 = Elasticsearch"가 된다.
그런데 정말 그래야 할까?
textsearch_ko 확장을 설치하면 MeCab 형태소 분석을 tsvector에 연결할 수 있다. pg_textsearch를 쓰면 BM25 스코어링이 가능하다. 여기에 pgvector로 밀집 벡터 검색을 더하고, SQL CTE로 BM25 + Dense 결과를 RRF로 합치면, PostgreSQL 하나로 하이브리드 검색 파이프라인이 완성된다.
문제는 "이 조합이 실제로 동작하는가"였다. 확장이 존재하는 것과 프로덕션 품질이 나오는 것은 별개 문제다. 8단계에 걸쳐 직접 측정했다.
실험에서 알게 된 것
토크나이저가 모든 것을 결정한다
한국어 BM25 품질의 대부분은 토크나이저 하나가 설명한다. Phase 1에서 MeCab, Kiwi, Okt 세 가지를 비교했는데, MeCab이 적절한 품질과 월등한 처리속도로 이후 모든 실험의 기본 토크나이저가 됐다.
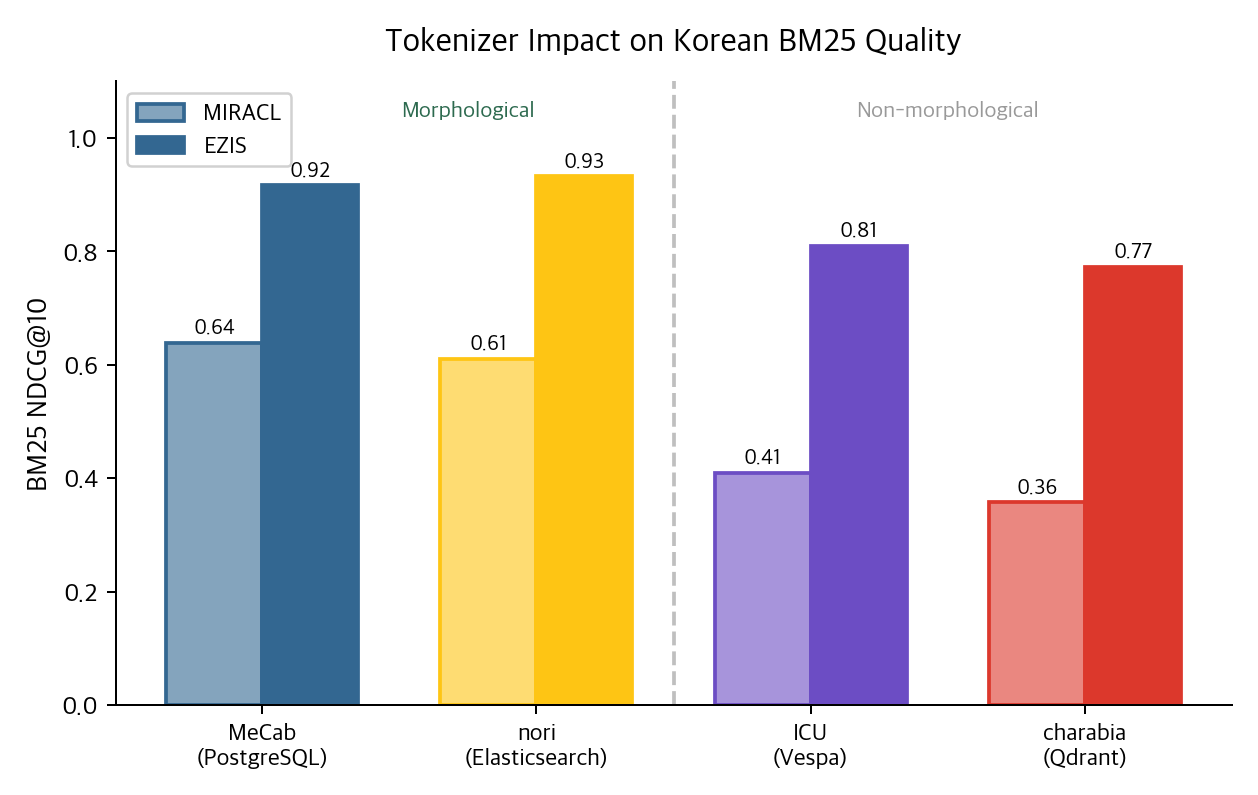
MeCab이나 nori처럼 형태소 분석을 하는 시스템(PostgreSQL, Elasticsearch)은 MIRACL BM25에서 NDCG 0.61~0.64를 달성한다. ICU 유니코드 경계 분리만 하는 Vespa는 0.41, Qdrant의 charabia(Meilisearch 유래 multilingual 토크나이저) 기반 Unicode 분리는 0.36이다.
형태소 분석이 없으면 "데이터베이스"와 "데이터"를 연결할 수 없다. "검색했다"와 "검색"이 별개 토큰이 된다. BM25가 아무리 정교해도 토큰이 틀리면 소용없다.
재미있는 발견이 하나 있다. Elasticsearch의 nori 토크나이저는 OR matching에서는 잘 작동하지만(NDCG 0.61), AND matching에서는 NDCG가 0.13까지 떨어진다. decompound_mode: mixed가 복합어를 과도하게 분해해서, 모든 토큰이 존재해야 하는 AND 조건에서 recall이 붕괴된다. 같은 AND 조건에서 PostgreSQL의 textsearch_ko는 0.64를 유지했다.
도메인에 따라 최적 방법이 뒤집힌다
성격이 다른 두 데이터셋을 병행 평가한 것이 이 실험 설계의 핵심이었다.
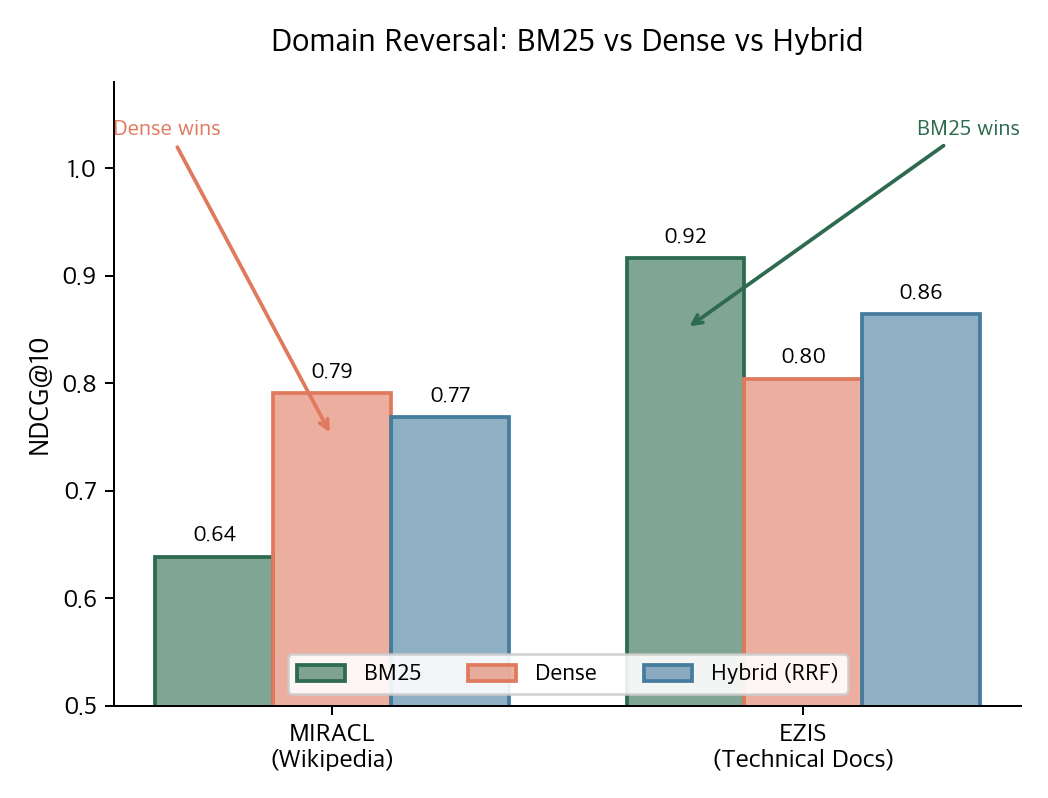
MIRACL(한국어 위키피디아)에서는 Dense 벡터 검색(0.79)이 BM25(0.64)를 크게 앞선다. 의미론적 유사도가 키워드 매칭보다 중요한 도메인이다.
EZIS(Oracle DB 매뉴얼)에서는 BM25(0.92)가 Dense(0.80)를 압도한다. "ORA-01555"나 "DBMS_STATS" 같은 정확한 용어 매칭이 의미 유사도보다 중요한 도메인이다.
같은 PostgreSQL 스택이, 같은 하이브리드 설정이, 데이터 성격에 따라 반대 결과를 내놓는다. "어떤 방법이 항상 최고"라는 결론은 불가능하다. 하이브리드(RRF)가 도메인을 모를 때의 안전한 선택인 이유다.
PostgreSQL이 전문 검색엔진/벡터DB보다 느리지 않다
직관적으로 전용 검색 엔진이 범용 DB보다 빠를 것 같지만, 측정 결과는 반대였다.
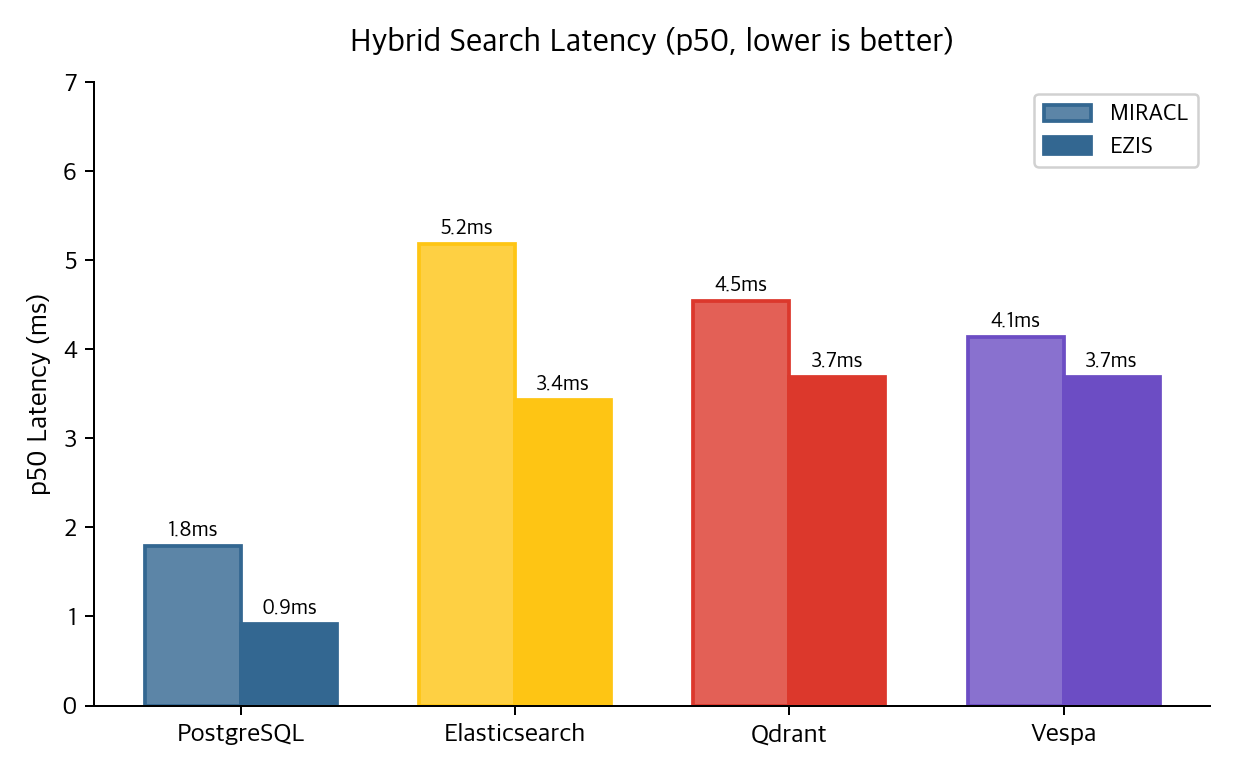
PostgreSQL의 DB-side RRF는 BM25 쿼리와 Dense 쿼리를 SQL CTE 안에서 실행하고 결과를 합친다. 애플리케이션과 DB 사이의 왕복이 한 번이다. ES나 Qdrant는 HTTP/JSON으로 요청을 주고받는다. 이 네트워크 오버헤드가 쿼리 자체보다 클 수 있다.
MIRACL 10K 기준 PostgreSQL RRF는 p50 1.79ms, ES는 5.18ms, Qdrant는 4.54ms, Vespa는 4.14ms. 단일 노드 로컬, warm-cache 측정이라는 점은 감안해야 한다. 그리고 Dense 검색의 latency에 BGE-M3 임베딩 추론 시간(~200ms)은 빠져 있다. 쿼리 임베딩을 사전 계산해두고 retrieval-only로 측정했다.
품질도 밀리지 않는다
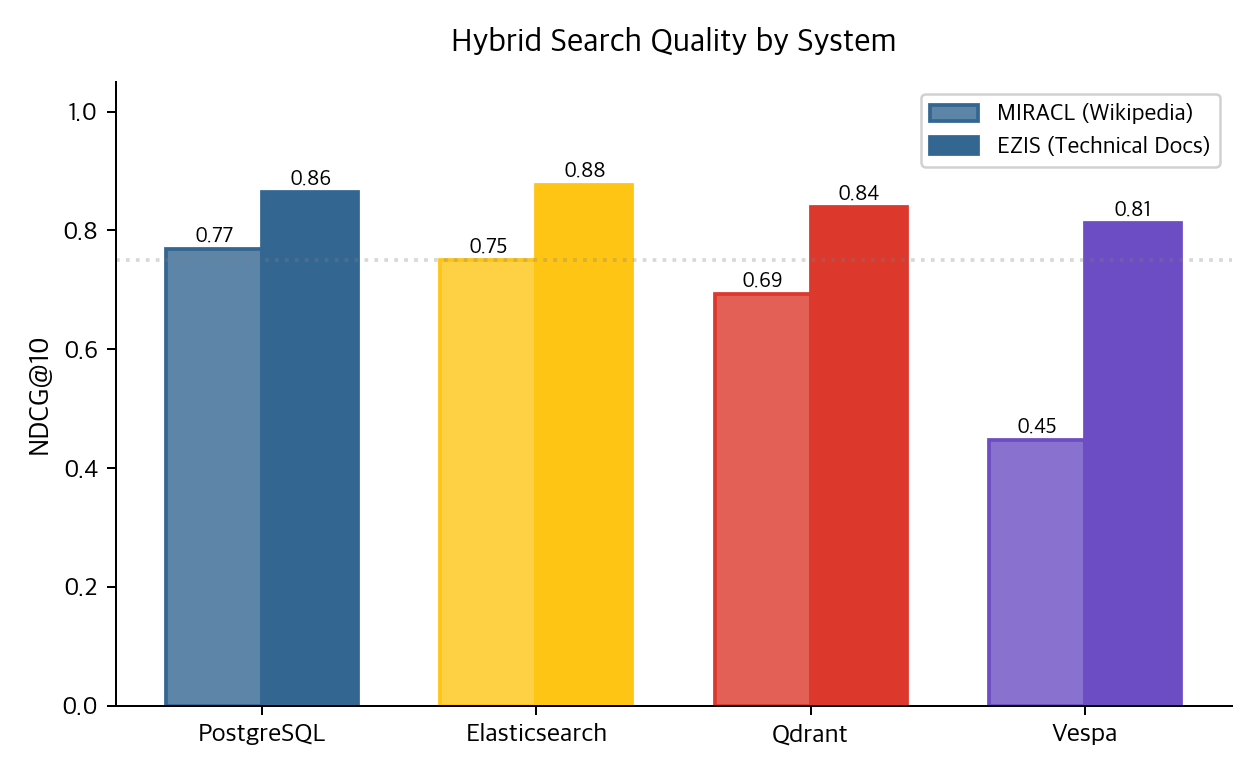
MIRACL Hybrid에서 PostgreSQL(0.77)은 Elasticsearch(0.75)보다 높다. EZIS에서는 ES(0.88)가 PG(0.86)를 근소하게 앞서지만, 통계적 유의성은 검증하지 않았다. Qdrant(0.69/0.84)와 Vespa(0.45/0.81)는 BM25 레그가 약한 만큼 Hybrid 품질도 따라 떨어진다.
Hybrid 품질은 BM25 품질에 그대로 종속된다. BM25 레그가 약하면 Hybrid가 오히려 품질을 깎는다. Vespa MIRACL Hybrid(0.45)가 Dense-only(0.79)보다 나쁜 게 그 증거다.
Qdrant에는 self-hosted BM25가 없다
Qdrant는 벡터 검색 전용 엔진으로서 구조적으로 가장 우수하다. 양자화, 필터링, 멀티테넌시, 대규모 분산까지 벡터 검색에 필요한 기능이 가장 풍부하다. 다만 한국어 텍스트 검색은 구조적으로 약하다.
qdrant/bm25라는 서버사이드 BM25 모델이 있지만 Qdrant Cloud 전용이라 self-hosted에서는 쓸 수 없다. 내장 텍스트 인덱스(TextIndexParams)의 multilingual 토크나이저는 Meilisearch에서 가져온 charabia 라이브러리 기반으로, Unicode 단어 경계 분리만 수행한다. 한국어 형태소 분석이 아니므로 "먹었다"와 "먹는"을 연결하지 못한다. 외부에서 MeCab으로 토크나이징한 뒤 sparse vector로 넣어봤는데, 이건 TF × IDF일 뿐 진짜 BM25가 아니다. 문서 길이 정규화(k1, b 파라미터)가 빠져 있어서 NDCG가 0.36에 그쳤다.
Vespa는 한국어 형태소 분석을 기본 지원하지 않는다
Vespa 자체는 BM25 + ANN hybrid를 선언적으로 잘 지원하는 시스템이다. 하지만 기본 토크나이저가 ICU(유니코드 경계 분리)라서 한국어 형태소 분석을 안 한다.
세 가지 경로로 한국어 형태소 분석기를 통합하려 시도했다. (1) Lucene Linguistics의 Nori: lucene-analysis-nori가 번들에 미포함이고 OSGi 격리로 실패. (2) 커스텀 Linguistics 컴포넌트(vespa-kuromoji-linguistics 패턴): Java 컴포넌트는 로드되지만, content node(proton, C++)가 인덱싱에 자체 ICU 토크나이저를 사용하여 인덱스/쿼리 토큰 불일치 발생. (3) set_language: Lucene Linguistics에 Nori가 없으므로 무의미. PostgreSQL이나 Elasticsearch와 달리 Vespa는 커스텀 토크나이저가 인덱싱과 쿼리 양쪽에 일관되게 적용되지 않는 구조다.
ICU BM25가 노이즈를 생성해서 0.1*bm25 + closeness 선형 결합 결과가 Dense-only(0.79)보다 나쁜 0.45를 기록했다.
주요 수치
시스템 간 비교 (Phase 8)
| 시스템 | MIRACL Hybrid | EZIS Hybrid | p50 |
|---|---|---|---|
| PostgreSQL (RRF) | 0.7683 | 0.8641 | 1.79ms |
| ES 8.17 (nori, retriever.rrf) | 0.7501 | 0.8769 | 5.18ms |
| Qdrant 1.15 (MeCab sparse + dense) | 0.6924 | 0.8394 | 4.54ms |
| Vespa (ICU + HNSW) | 0.4463 | 0.8125 | 4.14ms |
PostgreSQL 내부 비교 (Phase 7)
| 방법 | MIRACL NDCG@10 | EZIS NDCG@10 | p50 |
|---|---|---|---|
| pg_textsearch BM25 (MeCab) | 0.6385 | 0.9162 | 0.44ms |
| Dense (BGE-M3 HNSW) | 0.7904 | 0.8041 | 1.2ms |
| RRF hybrid (DB-side) | 0.7683 | 0.8641 | 1.79ms |
| Bayesian hybrid (DB-side) | 0.7272 | 0.9249 | 9.55ms |
BM25 스케일링 (Phase 6~7)
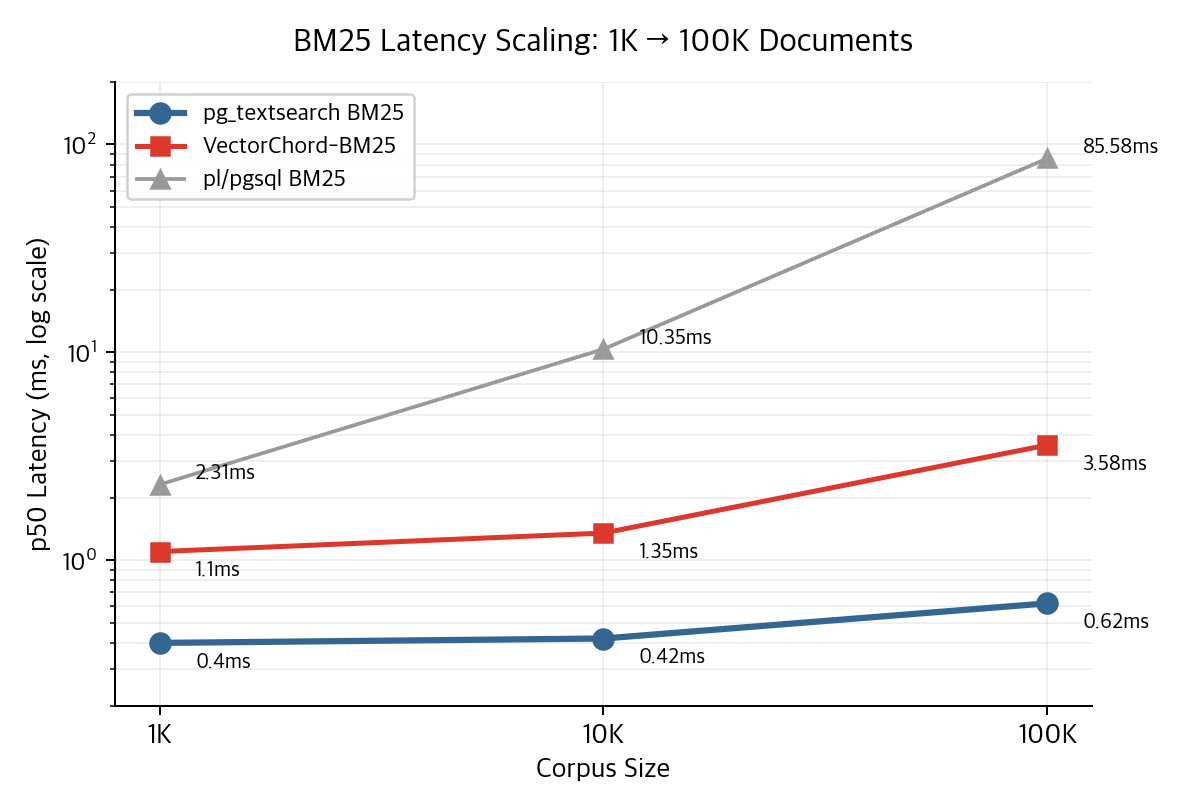
pg_textsearch는 100K 문서에서도 0.62ms를 유지한다. pl/pgsql 구현이 85ms로 폭발하는 것과 대비된다. 인덱스 크기도 18MB vs 501MB로 27배 차이다.
데이터셋
| 데이터셋 | 성격 | 쿼리 | 코퍼스 | 특징 |
|---|---|---|---|---|
| MIRACL-ko | 일반 위키피디아 | 213 | 10K | Dense 유리 |
| EZIS Oracle Manual | 기술 매뉴얼 | ~120 | ~200 | BM25 유리 |
성격이 다른 두 데이터셋을 병행 평가해서, "어떤 방법이 항상 최고"라는 착각을 방지했다.
실험 단계
| Phase | 무엇을 했나 | 핵심 발견 |
|---|---|---|
| 0 | MIRACL-ko + EZIS 데이터 준비 | — |
| 1 | 형태소 분석기 비교 (MeCab vs Kiwi vs Okt) | kiwi-cong 품질 1위, MeCab 속도 1위 → 속도·안정성 우선으로 MeCab 채택 |
| 2 | PostgreSQL tsvector 한국어 통합 | textsearch_ko로 MeCab → tsvector 연결 |
| 3 | PostgreSQL 내부 BM25 구현 비교 | pl/pgsql과 pg_textsearch 양강 |
| 4 | BM25 vs Neural (Dense, SPLADE) | 도메인에 따라 역전, hybrid가 안전 |
| 5 | Production 최적화 (incremental, concurrency) | pl/pgsql v2 + BGE-M3 조합 확정 |
| 6 | VectorChord-BM25 스케일링 (1K/10K/100K) | VectorChord가 pl/pgsql 대비 24배 빠름 |
| 7 | pg_textsearch 하이브리드 (RRF, Bayesian) | pg_textsearch가 전 스케일 최속, RRF 확정 |
| 8 | 외부 시스템 비교 (ES / Qdrant / Vespa) | PG 스택이 품질 동등, latency 2~5배 우위 |
측정 조건과 한계
- 모든 latency는 단일 노드, warm-cache, retrieval-only 측정이다.
- Dense 검색 latency에 BGE-M3 임베딩 추론 시간(~200ms)은 포함되지 않았다.
- PG 수치는 Phase 7 실측값 재사용이며, 동일 시점 head-to-head가 아닌 cross-phase 비교다.
- BM25 query semantics가 시스템마다 다르다는 것도 주의해야 한다: PG는 AND, ES는 OR, Vespa는 weakAnd.
- Bootstrap CI, p-value 등 통계적 유의성 검증은 미적용이다.
그래서 무엇을 쓸 것인가
새 프로젝트라면 PostgreSQL 하나로 시작하는 게 합리적이다. 토크나이저, BM25, 벡터, 하이브리드가 한 트랜잭션·한 노드·한 백업·한 권한 모델 안에 들어온다. 데이터 정합성 문제도, 검색 인덱스/원본 동기화 문제도 사라진다. 개인적으로는 이 운영 단순성이 latency 수치보다 더 설득력 있었다.
이미 Elasticsearch가 깔려 있고 nori AND 매칭만 안 쓴다면 굳이 옮길 이유는 없다. 한국어 품질은 nori OR 기준 PG와 동등하다. 다만 단일 노드 latency 우위와 운영 단순성은 분명한 이점이다.
Qdrant나 Vespa는 한국어 텍스트 검색을 1순위로 쓸 시스템이 아니다. 벡터 검색에 강점이 있는 시스템이고, 한국어 BM25는 외부에서 끌어와 붙여야 한다. 이 부분은 솔직히 아쉬운 대목이다. 벡터 인프라로는 Qdrant가 가장 성숙했는데, 텍스트 검색에서 이렇게 밀릴 줄은 몰랐다.
전체 코드와 phase별 상세 분석은 github.com/ysys143/textsearch에 공개해 두었다.