NVIDIA NIM API — GLM·Kimi·Nemotron·Gemma 4 무료 추론
NVIDIA는 build.nvidia.com에서 Z.ai GLM-5.1, Moonshot Kimi K2, NVIDIA Nemotron 3, Google Gemma 4 등 100개 이상의 대형 오픈소스 모델을 가속 인프라에서 무료로 제공하고 있습니다. 별도의 GPU 없이 API 키 하나로 호출할 수 있고, 신용카드도 필요 없습니다.
OpenAI API와 호환되는 구조라 Claude Code, Cursor 같은 코딩 에이전트에 그대로 연결해서 사용할 수 있습니다. 이 글에서는 API 키 발급부터 코딩 에이전트 연결, 주요 모델 활용까지 정리합니다.
API 키 발급
build.nvidia.com에서 무료 계정을 만들고 Get API Key → Generate Key를 누르면 발급됩니다. 키는 nvapi-로 시작하고 6개월 동안 유효합니다.
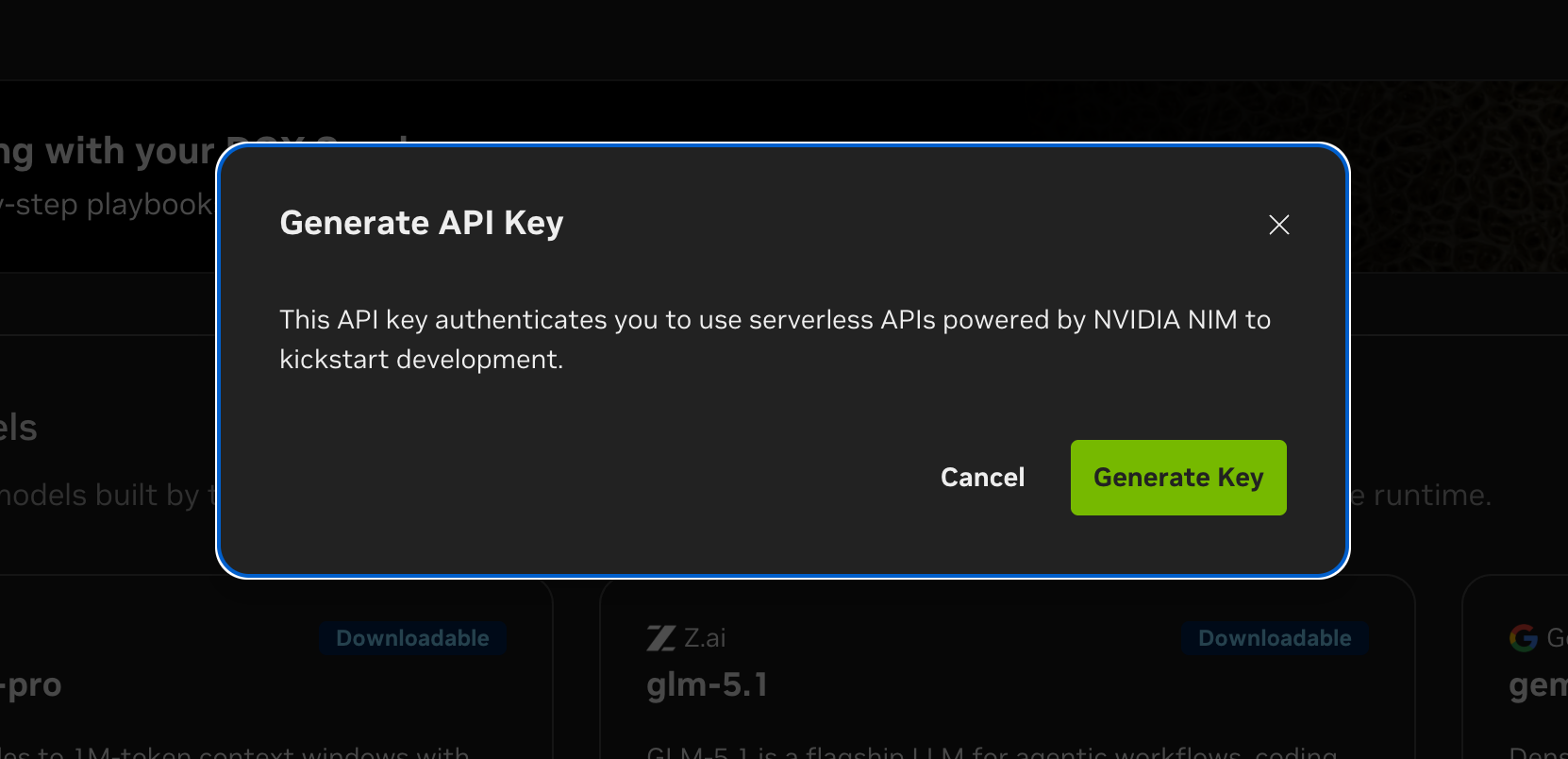
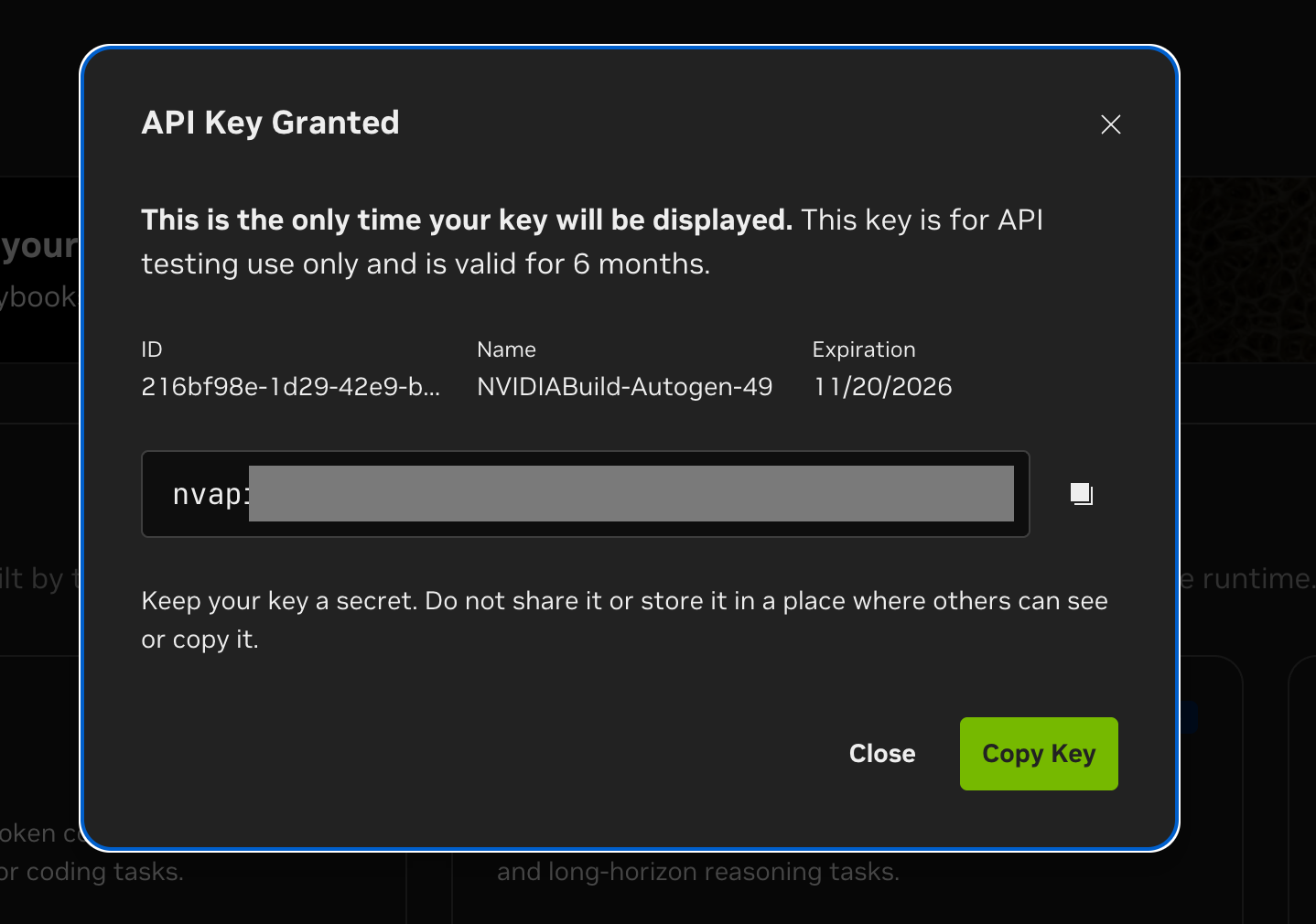
무료 티어 제약 (NVIDIA 공식 툴팁 기준):
- 최대 40 RPM 한도. 보장 처리량이 아니라 best-effort 상한입니다. 정확한 캡은 모델별로 다르고, 다른 사용자 트래픽에 따라 40 RPM에 못 미쳐도 throttling이 발생할 수 있습니다.
- 토큰 단위 과금 없음, 공식적으로 명시된 일일/월간 쿼터도 없음
- 키 유효기간 6개월 (대시보드에서 재발급)
본질적으로 공유 인프라 위에서 NVIDIA가 호의적으로 제공하는 자원에 가깝지 SLA가 있는 계약형 서비스가 아닙니다. 백그라운드 작업, 배치 처리, 가벼운 throttling을 감수할 수 있는 개인 사용에는 적합합니다. 안정적인 처리량이 필요하면 self-hosted NIM 전용 엔드포인트 배포가 NVIDIA가 권장하는 경로입니다.
프로토타이핑이나 개인 사용에는 40 RPM이 충분하지만, 병렬 도구 호출이 포함된 에이전트 루프에서는 한도에 자주 부딪힐 수 있습니다. 학술 연구, 에이전틱 워크플로우, 코딩 에이전트 같은 정당한 사유가 있으면 NVIDIA Developer Forums에 사용 사례를 짧게 설명하고 신청하면 200 RPM으로 상향이 가능합니다.
코딩 에이전트에 연결하기
Claude Code
NVIDIA 공식 문서에 Claude Code 연결 방법이 명시되어 있습니다. 환경변수로 엔드포인트를 교체하면 됩니다.
export ANTHROPIC_API_KEY="nvapi-YOUR_KEY_HERE"
export ANTHROPIC_BASE_URL="https://integrate.api.nvidia.com/v1"
export ANTHROPIC_CUSTOM_MODEL_OPTION="deepseek-ai/deepseek-v4-pro"
export ANTHROPIC_DEFAULT_HAIKU_MODEL="deepseek-ai/deepseek-v4-pro"
export ANTHROPIC_DEFAULT_SONNET_MODEL="deepseek-ai/deepseek-v4-pro"
export ANTHROPIC_DEFAULT_OPUS_MODEL="deepseek-ai/deepseek-v4-pro"
export CLAUDE_CODE_SUBAGENT_MODEL="deepseek-ai/deepseek-v4-pro"설정 후 claude를 실행하면 Anthropic 대신 NVIDIA 인프라로 요청이 전달됩니다. 코딩 특화 모델을 원하면 mistralai/devstral-small-2505, 에이전틱 워크플로우에는 z-ai/glm-5.1로 교체할 수 있습니다.
Cursor / Continue / OpenCode
OpenAI 호환 에이전트는 동일한 방법으로 연결됩니다. Cursor 기준으로는 Settings → Models → Add Model에서 아래와 같이 입력합니다.
Base URL: https://integrate.api.nvidia.com/v1
API Key: nvapi-YOUR_KEY_HERE
Model: deepseek-ai/deepseek-v4-proContinue, OpenCode 등 baseURL을 직접 지정할 수 있는 에이전트라면 방법이 같습니다.
기본 API 사용법
OpenAI Python SDK를 그대로 사용합니다.
pip install openaibuild.nvidia.com에서 원하는 모델을 선택하고 View Code를 누르면 복사해서 바로 쓸 수 있는 코드가 표시됩니다.
Quick Start 코드는 이런 형태입니다.
import os
from openai import OpenAI
client = OpenAI(
base_url="https://integrate.api.nvidia.com/v1",
api_key=os.getenv("NVIDIA_API_KEY"),
)
completion = client.chat.completions.create(
model="nvidia/nemotron-3-nano-omni-30b-a3b-reasoning",
messages=[{"role": "user", "content": "2+2는 얼마야?"}],
temperature=0.6,
top_p=0.95,
max_tokens=65536,
extra_body={
"chat_template_kwargs": {"enable_thinking": True},
"reasoning_budget": 16384,
},
stream=False,
)
print(completion.choices[0].message.content)extra_body 필드는 OpenAI 호환 API로 NVIDIA가 모델별 옵션을 노출하는 방식입니다. 추론 모델은 enable_thinking과 reasoning_budget을 받습니다.
스트리밍
response = client.chat.completions.create(
model="deepseek-ai/deepseek-v4-pro",
messages=[{"role": "user", "content": "REST API 설계 원칙을 설명해줘"}],
stream=True,
)
for chunk in response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)추론 모델: 사고 과정과 최종 답변 분리하기
NIM의 추론 모델들(Nemotron reasoning 변형, DeepSeek V4, GLM-5.1)은 사고 과정을 본문 안의 <think> 태그가 아니라 별도 필드로 반환합니다. OpenAI SDK에서는 message 객체의 reasoning_content 속성으로 접근합니다.
completion = client.chat.completions.create(
model="nvidia/nemotron-3-nano-omni-30b-a3b-reasoning",
messages=[{
"role": "user",
"content": "이 함수의 시간 복잡도를 분석해줘:\n\ndef find_duplicates(arr):\n result = []\n for i in range(len(arr)):\n for j in range(i+1, len(arr)):\n if arr[i] == arr[j] and arr[i] not in result:\n result.append(arr[i])\n return result"
}],
temperature=0.6,
top_p=0.95,
max_tokens=4096,
extra_body={
"chat_template_kwargs": {"enable_thinking": True},
"reasoning_budget": 8192,
},
)
msg = completion.choices[0].message
reasoning = getattr(msg, "reasoning_content", None)
if reasoning:
print("[추론 과정]", reasoning)
print("[최종 답변]", msg.content)"2+2는 얼마야?" 같은 간단한 요청에서도 추론 과정이 분리되어 나옵니다.
[추론 과정] The user asks in Korean: "2+2는 얼마야?" which means "What is 2+2?"
The answer is 4. Should respond in Korean.
[최종 답변] 2 + 2 = 4.reasoning_content를 따로 다룰 수 있어서 프롬프트 디버깅, UI에 사고 과정 표시, 로그에서 thinking 제거 등에 유용합니다.
주요 모델 카탈로그
build.nvidia.com 카탈로그의 주요 모델:
| 모델 | 특징 |
|---|---|
deepseek-ai/deepseek-v4-pro |
1M 컨텍스트 MoE, 코딩 및 추론 |
z-ai/glm-5.1 |
에이전틱 워크플로우, 장기 추론 플래그십 |
google/gemma-4-31b-it |
Dense 31B, 추론 특화, 파인튜닝 가능 |
nvidia/nemotron-3-super-120b-a12b |
120B Mamba-Transformer MoE, 1M 컨텍스트 |
nvidia/nemotron-3-nano-omni-30b-a3b-reasoning |
30B 옴니모달 추론 |
mistralai/devstral-small-2505 |
코딩 특화 |
임베딩
response = client.embeddings.create(
model="nvidia/nv-embedqa-e5-v5",
input="RAG 시스템에 넣을 텍스트",
encoding_format="float",
)
embedding = response.data[0].embedding비전 (옴니모달)
import base64
with open("screenshot.png", "rb") as f:
image_b64 = base64.b64encode(f.read()).decode()
response = client.chat.completions.create(
model="nvidia/nemotron-3-nano-omni-30b-a3b-reasoning",
messages=[{
"role": "user",
"content": [
{"type": "text", "text": "이 코드 스크린샷에서 버그를 찾아줘"},
{"type": "image_url", "image_url": {"url": f"data:image/png;base64,{image_b64}"}},
],
}],
)전체 모델 목록 조회
models = client.models.list()
for model in models.data:
print(model.id)