PG-Strom SSB 벤치마크 — GPU보다 Arrow FDW가 먼저다
PG-Strom 소개 문서를 처음 읽으면 단순하게 들립니다. PostgreSQL에 extension을 하나 설치하면 쿼리가 GPU에서 실행된다는 내용입니다. 실제로 세 개 서버 환경에서 555개 테스트 케이스를 돌려보면 이 설명이 절반만 맞다는 걸 알게 됩니다. GPU를 붙여도 Arrow FDW 없이는 1.6배 가속에 그칩니다. wide table에서는 오히려 CPU보다 느려집니다. 반면 Arrow FDW를 함께 쓰면 SF=100(약 600GB) 기준으로 10배 이상 빠릅니다.
차이를 만드는 것은 GPU 스펙이 아닙니다. 데이터가 GPU에 얼마나 빠르게, 얼마나 적게 도달하는가입니다.
PG-Strom이 하는 일과 병목의 위치
일반 PostgreSQL 쿼리 실행 경로는 다음과 같습니다.
디스크(SSD/NVMe) → OS page cache → shared_buffers → CPU executor → 결과 반환PG-Strom이 활성화되면 집계, 스캔, 필터 연산을 GPU로 offload합니다.
디스크 → OS page cache → RAM → PCIe 버스 → GPU VRAM → CUDA 커널 → 결과GPU는 수천 개의 코어가 동일 연산을 병렬로 수행하는 아키텍처입니다. SUM(price * discount), GROUP BY region 같은 집계 연산은 이 병렬성의 혜택을 받습니다. L40S 기준으로 CUDA 코어가 18,176개입니다. 같은 연산을 CPU가 처리하면 물리 코어 수십 개를 쓰는 것과 대조됩니다.
하지만 GPU 코어가 아무리 많아도, 처리할 데이터가 GPU VRAM에 도달하지 못하면 코어들은 기다립니다. GPU와 CPU 사이를 잇는 PCIe 버스의 대역폭이 병목입니다.
PCIe 4.0 × 16 이론 대역폭: 약 32 GB/s
디스크에서 데이터를 읽으면 NVMe → CPU RAM → PCIe → GPU VRAM 경로를 거칩니다. GPU가 연산하기 전에 이 전송이 완료돼야 합니다. GPUDirect Storage(GDS)를 쓰면 CPU RAM을 거치지 않고 NVMe → PCIe → GPU VRAM으로 단축됩니다(Server B에서 GDS는 비활성화하고 기본 I/O 경로만 측정했습니다).
이 PCIe 전송 비용이 PG-Strom 성능의 진짜 결정 요인입니다. GPU 코어 수나 CUDA 버전보다 데이터 전송량이 더 중요합니다.
테스트 환경 세 개
| 서버 | CPU | GPU | 스토리지 | 측정 목적 |
|---|---|---|---|---|
| Server A | Xeon Gold 6526Y × 2 (32코어/64스레드, 2.8GHz/최대 3.8GHz) | L40S 48GB × 3 (라이선스 제약으로 단일 GPU 활성화) | SATA SSD 1.92TB × 4 | 기본 SSB + GPU Cache 검증 |
| Server B | Xeon Gold 6448H × 2 (64코어/128스레드, 2.4GHz/최대 4.1GHz) | L40S 48GB × 1 (PCIe 5.0) | NVMe SSD 894GB × 2 | Scale Factor 1→100 sweep |
| Server C | GCP g2-standard-4 (2코어, 16GB RAM) | L4 23GB × 1 (PCIe 4.0) | NVMe 375GB local + 100GB | OLAP 엔진 비교 + 벡터 검색 |
L40S는 Ada Lovelace 아키텍처 GPU로 VRAM 48GB, CUDA 13.0입니다. L4는 클라우드용 엔트리 GPU입니다. Server A는 GPU가 3개이지만 XCruzDB 라이선스 제약으로 1개만 활성화했습니다.
벤치마크 워크로드는 Star Schema Benchmark(SSB) q1.1~q4.3 13개 쿼리입니다. SSB는 TPC-H를 데이터 웨어하우스 패턴에 맞게 재구성한 표준 벤치마크로, 대용량 lineorder 팩트 테이블과 소규모 차원 테이블(supplier, customer, part, date) 간 JOIN 집계가 핵심입니다. Scale Factor 1 = lineorder 약 600만 행 / 약 6GB, SF=100 = 약 6억 행 / 약 600GB입니다.
모든 측정은 OS 캐시를 초기화한 cold 상태와 반복 실행 후 warm 상태를 각각 기록했습니다. 각 쿼리는 최소 5회 반복 실행해 변동계수(CV) 10% 이하를 목표로 했습니다.
Heap vs Arrow FDW: 스토리지 포맷이 모든 것을 결정한다
PG-Strom 가속의 전제 조건인 Arrow FDW를 먼저 이해해야 합니다.
PostgreSQL Heap 스토리지
PostgreSQL의 기본 스토리지 포맷은 Heap입니다. 행(row) 단위로 저장합니다. 테이블에 17개 컬럼이 있으면 각 행은 17개 컬럼 값을 연속으로 포함합니다.
Page 1:
[row1: lo_orderkey, lo_linenumber, lo_custkey, ..., lo_supplycost, lo_ordtotalprice, lo_revenue]
[row2: lo_orderkey, lo_linenumber, lo_custkey, ..., lo_supplycost, lo_ordtotalprice, lo_revenue]
...SSB q1.1 쿼리가 실제로 참조하는 컬럼은 3~4개입니다.
-- SSB q1.1
SELECT SUM(lo_extendedprice * lo_discount) AS revenue
FROM lineorder, date
WHERE lo_orderdate = d_datekey
AND d_year = 1993
AND lo_discount BETWEEN 1 AND 3
AND lo_quantity < 25;lo_extendedprice, lo_discount, lo_orderdate, lo_quantity, 이 4개 컬럼만 필요합니다. 하지만 Heap 스토리지는 WHERE 조건 평가와 집계 연산을 위해 전체 행을 읽어야 합니다. 17개 컬럼 중 4개만 쓰이지만 디스크에서 읽히는 건 17개 컬럼입니다.
Apache Arrow FDW
Arrow FDW는 Apache Arrow 컬럼 포맷 파일을 PostgreSQL에서 외부 테이블(FDW)로 읽는 방식입니다. Apache Arrow는 컬럼별로 연속된 메모리 블록에 데이터를 저장합니다.
Arrow 파일 구조:
[lo_orderkey 블록: val1, val2, ..., val6000000]
[lo_linenumber 블록: val1, val2, ..., val6000000]
...
[lo_extendedprice 블록: val1, val2, ..., val6000000]
[lo_discount 블록: val1, val2, ..., val6000000]
...q1.1 쿼리를 처리할 때 Arrow FDW는 lo_extendedprice, lo_discount, lo_orderdate, lo_quantity 블록만 읽습니다. 17개 컬럼 중 4개 = 약 24%의 I/O만 발생합니다.
PCIe 전송량 계산
lineorder SF=1 기준(600만 행):
- Heap: 전체 17컬럼 × 평균 8바이트 × 600만 행 ≈ 816MB 전송
- Arrow FDW (4컬럼): 4컬럼 × 8바이트 × 600만 행 ≈ 192MB 전송
PCIe 4.0 × 16(32 GB/s) 기준 전송 시간:
- Heap: 816MB ÷ 32GB/s ≈ 25ms (이론치)
- Arrow: 192MB ÷ 32GB/s ≈ 6ms
실제로는 디스크 I/O, DMA 오버헤드 등이 추가되지만 비율은 유지됩니다. Arrow FDW가 전송해야 할 데이터가 적으니 GPU 코어들이 더 빨리 작업을 시작할 수 있습니다.
SF=1 실측: 같은 GPU, 같은 쿼리, 다른 스토리지
Server B(NVMe, L40S) 환경에서 SF=1 기준 13개 SSB 쿼리 속도비를 비교했습니다.
| 조합 | GPU/CPU 속도비 |
|---|---|
| Arrow + GPU | 12.4배 |
| Arrow + CPU | 기준 |
| Heap + GPU | 1.6배 |
| Heap + CPU | 기준 |
Arrow+GPU가 12.4배인 반면 Heap+GPU는 1.6배입니다. 같은 L40S GPU를 사용하는데 스토리지 포맷만 달라집니다.
더 극단적인 경우가 있었습니다. 50개 이상 컬럼을 가진 wide table에서 2~3개 컬럼만 SELECT할 때, Heap+GPU가 CPU만 쓸 때보다 18~27% 느렸습니다.
수치로 설명하면 이렇습니다. t_wide 테이블이 50컬럼이고 각 컬럼이 8바이트라면 행당 400바이트입니다. 10M 행 테이블을 읽으면 4GB를 GPU로 전송해야 합니다. PCIe 전송 시간: 4GB ÷ 32GB/s = 125ms. 이 125ms 동안 GPU 코어들은 데이터를 기다립니다. 실제 집계 연산(SUM, GROUP BY)은 수 ms면 끝납니다. 전송 대기가 연산 시간을 압도합니다.
CPU는 이 비용이 없습니다. shared_buffers나 OS page cache에 이미 올라온 데이터는 L3 캐시를 거쳐 즉시 처리됩니다. 따라서 Heap wide table에서는 "GPU로 데이터 보내는 비용 > GPU 연산으로 얻는 이득"이 됩니다.
Arrow FDW를 쓰면 2~3개 컬럼만 전송하니 전송 시간이 4~6ms로 줄고, GPU가 즉시 작업을 시작합니다.
결론: PG-Strom 성능 공식은 GPU 연산 속도가 아니라 전송 데이터 최소화 × GPU 병렬 연산입니다. Arrow FDW가 앞부분을, GPU가 뒷부분을 담당합니다.
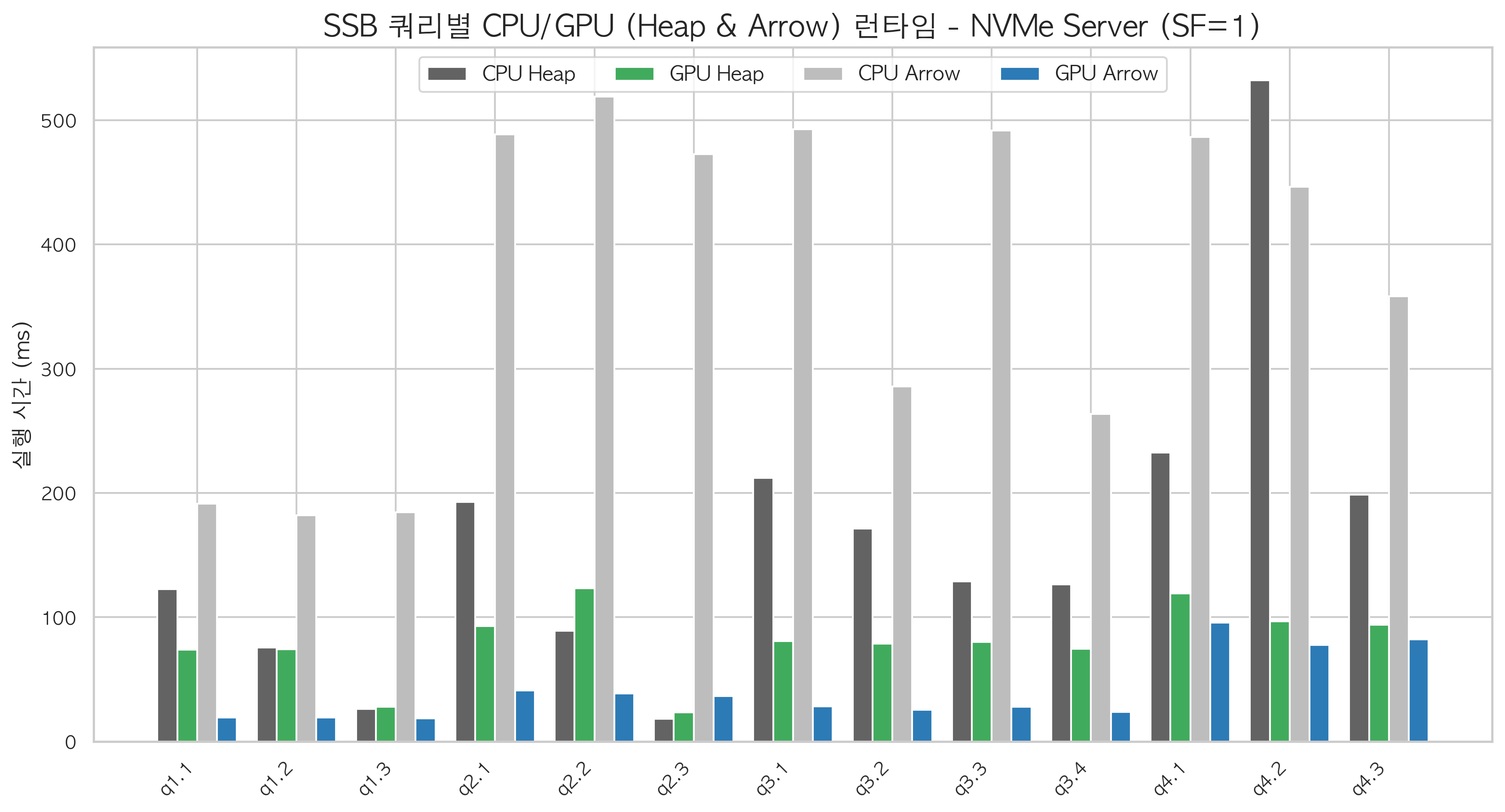
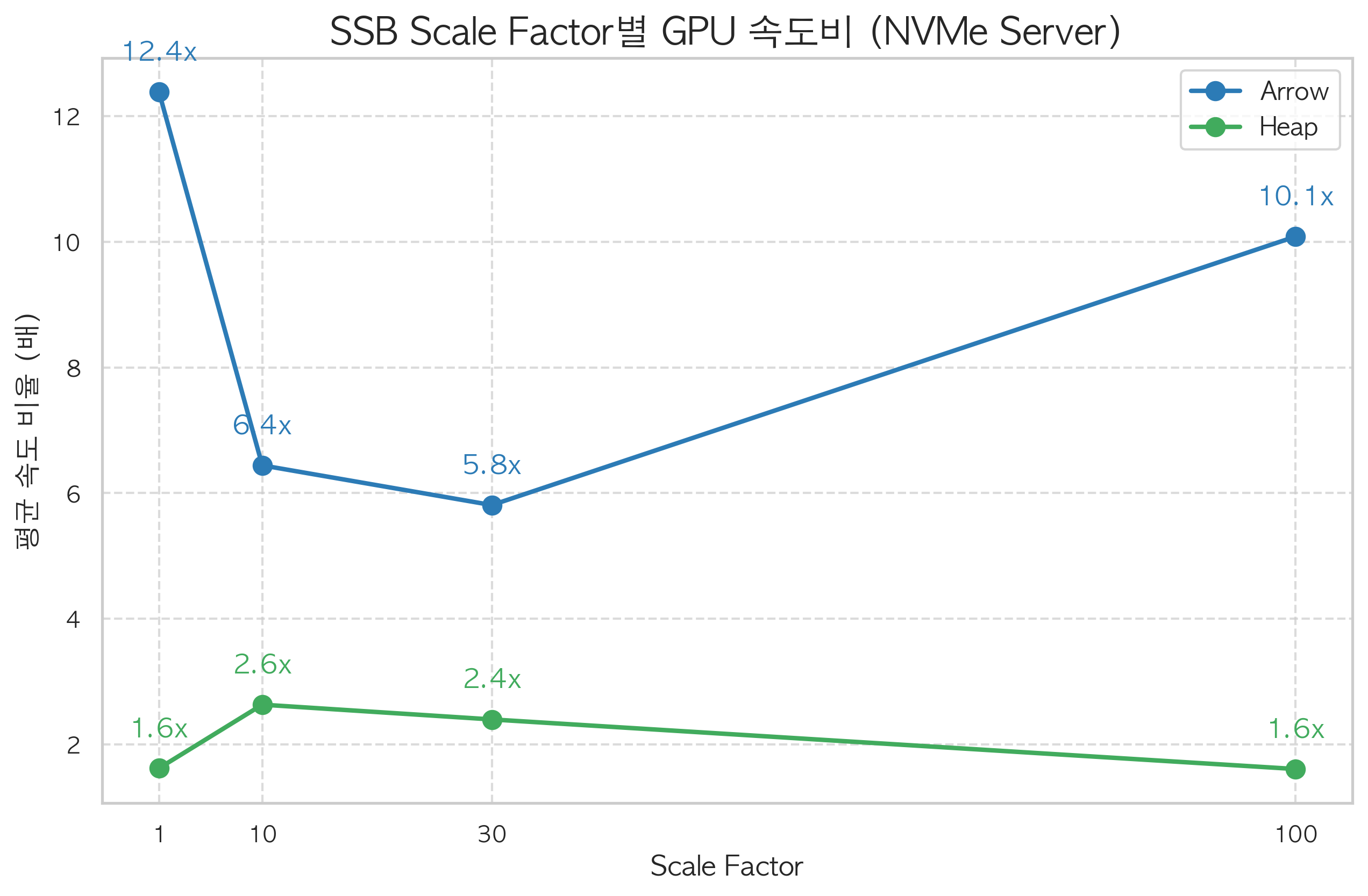
Scale Factor 1→100: 데이터가 클수록 격차가 커진다
Server B(NVMe)에서 SF를 1에서 100까지 올리며 측정했습니다.
| SF | 데이터 크기 | Arrow GPU/CPU 속도비 | Heap GPU/CPU | Arrow+GPU 총 실행시간 | CPU+Arrow 총 시간 |
|---|---|---|---|---|---|
| 1 | ~6GB | 12.4배 | 1.6배 | 4.6초 | 36.5초 |
| 10 | ~60GB | 6.4배 | 2.6배 | 5.9초 | 28.3초 |
| 30 | ~180GB | 5.8배 | 2.4배 | 14.1초 | 65.2초 |
| 100 | ~600GB | 10.1배 | 1.6배 | 21.5초 | 221.0초 |
SF=10에서 SF=30으로 넘어갈 때 속도비가 6.4배 → 5.8배로 소폭 감소합니다. 데이터 크기가 NVMe 순차 읽기 대역폭의 포화점에 가까워지기 때문입니다. Arrow FDW가 불필요한 컬럼을 건너뛰어도 팩트 테이블 자체가 크면 I/O 절대량이 늘어납니다.
SF=100에서 속도비가 10배로 회복됩니다. 이 구간에서는 쿼리가 여러 컬럼을 함께 읽는 비율이 높아 Arrow의 컬럼 선택적 읽기 효과가 극대화됩니다. 절대 시간으로는 Arrow+GPU 21.5초 vs CPU+Arrow 221초로 10배 차이가 납니다.
Heap+GPU는 SF에 상관없이 1.6배에 머뭅니다. 데이터가 커질수록 PCIe 전송 시간도 비례해서 늘어나 가속 효과가 희석됩니다.
GPU Cache: PCIe 병목 자체를 없애는 방법
Arrow FDW로도 부족한 경우가 있습니다. PCIe 전송이 여전히 발생하기 때문입니다. gpucache trigger를 테이블에 설치하면 데이터가 GPU VRAM에 상주합니다. 이후 쿼리는 디스크나 RAM에서 데이터를 가져올 필요가 없습니다.
Server A 환경에서 t_big_cache(10M 행) 집계 케이스를 측정했습니다.
| 케이스 | GPU ON | GPU OFF | 속도비 |
|---|---|---|---|
t_big_cache (GPU Cache ON) |
39.26ms | 2,525.79ms | 64.3배 |
| Arrow FDW full scan (346MB) | 21.34ms | 810.58ms | 38.0배 |
GPU Cache가 Arrow FDW보다 1.7배 빠릅니다. 전송 경로 자체가 없어서입니다. GPU 코어들이 VRAM에 있는 데이터를 바로 처리합니다.
운영 현실을 따지면 GPU Cache의 적용 범위는 제한적입니다.
적합한 테이블:
- VRAM 크기(L40S 48GB) 이하인 테이블
- 갱신이 드물고 집계 빈도가 높은 테이블(차원 테이블: 날짜, 지역, 제품 코드 등)
- 수백만 행 이하의 룩업 테이블
부적합한 테이블:
- 수십억 행 팩트 테이블: VRAM을 초과합니다
- 실시간 갱신 테이블:
gpucachetrigger가 INSERT/UPDATE/DELETE마다 VRAM을 동기화해야 합니다
실전에서 GPU Cache는 차원 테이블이나 집계 결과 캐시에 적용하고, 대용량 팩트는 Arrow FDW로 처리하는 혼합 전략이 현실적입니다.
다른 OLAP 엔진과의 비교
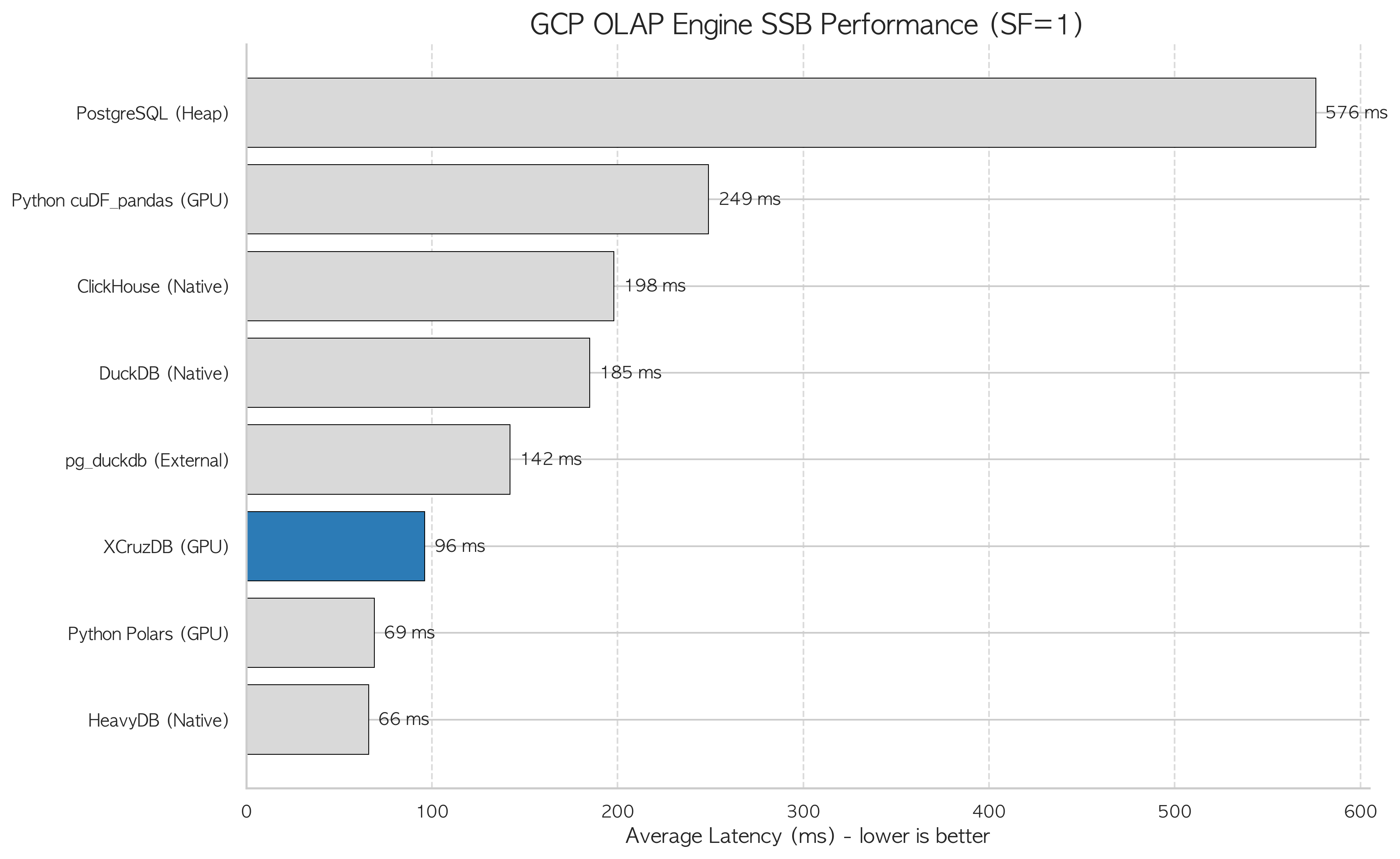
GCP Server C(L4 GPU)에서 SSB SF=1 기준으로 여러 OLAP 엔진을 비교했습니다. PG-Strom이 어디에 위치하는지 맥락을 파악하기 위한 측정입니다.
| 순위 | 엔진 | 평균 실행시간 (ms) | PostgreSQL Heap 대비 | 비고 |
|---|---|---|---|---|
| 1 | HeavyDB | 66 | 8.7배 | GPU 네이티브 DB, Warm cache 기준 |
| 2 | Python Polars (GPU) | 69 | 8.3배 | Lazy evaluation + GPU RAPIDS |
| 3 | PG-Strom/XCruzDB (GPU) | 96 | 6.0배 | PostgreSQL 생태계 유지 |
| 4 | pg_duckdb (Parquet) | 142 | 4.2배 | PG + DuckDB 하이브리드, GPU 불필요 |
| 5 | DuckDB native | 185 | 3.1배 | CPU 벡터화, 독립 프로세스 |
| 6 | ClickHouse | 198 | 2.9배 | CPU 최적화 컬럼형 DB |
| — | Python cuDF_pandas | 249 | 2.4배 | pandas API 호환 GPU DataFrame |
| — | PostgreSQL Heap | 576 | 기준 | — |
HeavyDB가 66ms로 가장 빠릅니다. GPU 데이터베이스 전용 아키텍처입니다. 하지만 PostgreSQL을 버려야 합니다. 기존 스키마, 애플리케이션 쿼리, pgvector, PostGIS, 모니터링 설정을 전부 HeavyDB로 마이그레이션해야 합니다.
PG-Strom은 PostgreSQL 위에 얹어 96ms를 달성합니다. DuckDB(185ms)나 ClickHouse(198ms)보다 약 2배 빠르면서 PostgreSQL 생태계를 그대로 유지합니다.
pg_duckdb(142ms)는 흥미로운 위치입니다. GPU 없이도 4.2배를 달성합니다. PostgreSQL 안에서 DuckDB 엔진이 Parquet를 읽는 방식으로, Arrow FDW와 유사한 컬럼 I/O 효율을 GPU 없이 얻습니다.
PG-Strom의 가치는 명확합니다. GPU가 있고, PostgreSQL 생태계 유지가 조건이고, OLAP 성능 개선이 필요할 때 DuckDB·ClickHouse 대비 2배의 추가 이득을 줍니다.
GCS: 클라우드 스토리지에서의 현실
NVMe 측정과 별개로 GCS(Google Cloud Storage)에서 TPC-H SF=100 22개 쿼리를 실행했습니다. Lakehouse 아키텍처에서 오브젝트 스토리지를 쓸 때의 현실적인 성능 기준을 확인하기 위해서였습니다.
| 환경 | NVMe 대비 성능 |
|---|---|
| Local NVMe | 기준 (1×) |
| GCS cold query (최초 실행) | 약 650배 느림 |
| GCS + 세션 캐시 (재실행) | 약 2.6배 느림 |
첫 번째 쿼리가 GCS에서 실행되면 NVMe 대비 650배 느립니다. HTTP over TLS로 오브젝트를 fetch하고, 네트워크 레이턴시와 GCS 스로틀링이 더해집니다. 100GB 데이터를 네트워크로 읽는 건 NVMe에서 읽는 것과 같을 수 없습니다.
세션 캐시가 활성화되면 두 번째 실행부터 2.6배 수준으로 회복됩니다. 하지만 이것은 캐시 적중을 전제로 합니다. 새로운 쿼리, 다른 필터 조건, 시간이 지나 캐시가 eviction된 경우에는 다시 cold read입니다.
22개 TPC-H 쿼리가 모두 성공했고 SF=100(866M 행) 스케일에서 정확성은 확인됐습니다. 하지만 프로덕션 SLA를 잡으려면 캐싱 전략 없이 GCS만 믿는 것은 위험합니다.
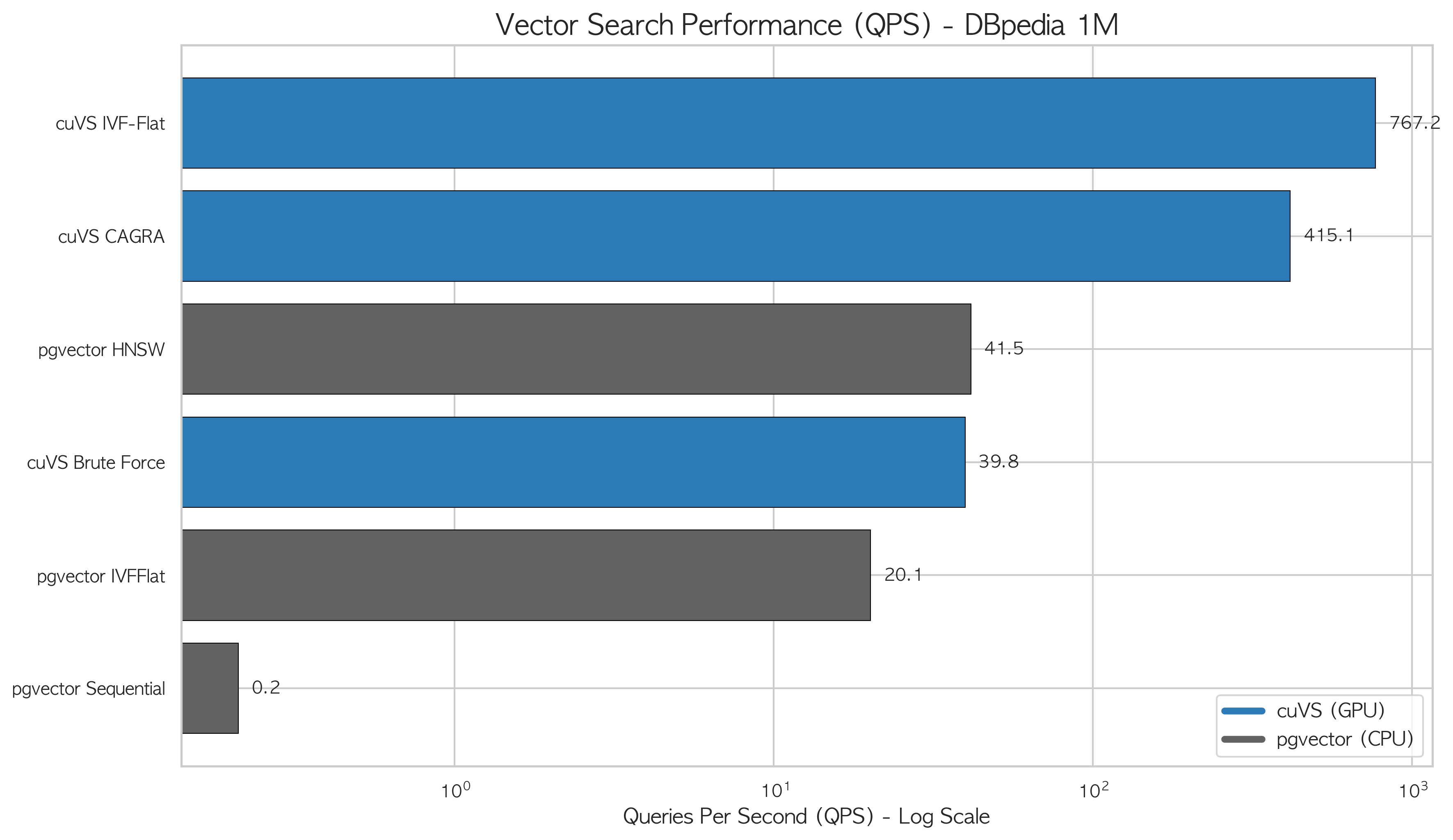
벡터 검색: cuVS vs pgvector
PG-Strom 벤치마크의 부산물로 GPU 벡터 검색도 측정했습니다. Server C에서 DBpedia Wikipedia 엔티티 임베딩 1M 벡터(1,536차원)를 사용해 NVIDIA cuVS와 pgvector를 비교했습니다.
측정 방법
100개 쿼리 벡터에 대해 top-10 결과를 반환하는 ANN 검색을 측정했습니다. Warm cache 기준입니다.
| 방법 | 평균 지연시간 (ms) | QPS | Recall@10 | 인덱스 빌드 시간 |
|---|---|---|---|---|
| cuVS Brute Force | 24.19 | 39.76 | 1.000 | 없음 |
| cuVS IVF-Flat | 1.32 | 767 | 0.928 | 3.47초 |
| cuVS CAGRA | 2.40 | 415 | 0.986 | 22.77초 |
| pgvector Sequential | 4,757.64 | 0.21 | 1.000 | 없음 |
| pgvector IVFFlat | 49.85 | 20.06 | 0.876 | 288.79초 |
| pgvector HNSW | 24.12 | 41.46 | 0.941 | 810.62초 |
cuVS IVF-Flat이 767 QPS로 pgvector HNSW(41 QPS) 대비 18.7배 높은 처리량을 기록했습니다. 인덱스 빌드 시간은 3.5초 vs 13.5분으로 230배 차이입니다.
왜 이런 차이가 나는가
pgvector HNSW는 CPU에서 계층적 그래프를 탐색합니다. 각 검색이 그래프 노드를 하나씩 포인터 체이싱하며 이동하는 구조입니다. 동시 검색 연산들이 공유 그래프 구조에 접근하며 경합이 생깁니다.
cuVS IVF-Flat은 1M 벡터를 클러스터로 분할하고, 쿼리 벡터와 가장 가까운 클러스터 내에서 GPU 코어들이 병렬로 거리를 계산합니다. 1,536차원 벡터의 내적 연산(dot product)은 SIMD에 완벽히 맞는 패턴으로, 수백 개 CUDA 코어가 동시에 처리합니다.
Recall 면에서 IVF-Flat(0.928)이 HNSW(0.941)보다 낮습니다. ANN 특성상 클러스터 경계 근처 벡터를 놓칠 수 있습니다. cuVS CAGRA는 0.986 Recall로 HNSW를 앞서면서 QPS는 10배 높습니다. 정확도와 처리량을 함께 원한다면 CAGRA가 최선입니다.
PG-Strom과의 관계
PG-Strom은 현재 float array 벡터 연산을 직접 지원하지 않습니다. cuVS는 PG-Strom과 별도 레이어에서 동작합니다. 같은 PostgreSQL 인스턴스에서 OLAP 집계는 PG-Strom이, 벡터 검색은 cuVS가 담당하는 분리된 구조입니다.
이 결과를 바탕으로 cuVS를 PostgreSQL extension(pg_cuvs)으로 통합하는 작업도 진행했습니다. Python 래퍼 대신 PostgreSQL SPI와 직접 연동해 오버헤드를 제거합니다.
PostGIS GIS 워크로드: geometry vs geography
PostGIS와 PG-Strom 조합에서 발견한 제약도 기록해둡니다. Server A에서 Point/Polygon 지리공간 쿼리를 측정했을 때 결과가 두 갈래로 나뉩니다.
geometry 타입 연산(ST_Within, ST_Intersects 등)은 GPU 가속이 적용됩니다. 50M 포인트와 1K 폴리곤 매칭에서 3~21배 속도 향상을 기록했습니다.
geography 타입 함수(ST_DWithin(geography, ...) 등)는 GPU에서 미지원입니다. CPU 폴백이 발생해 GPU ON/OFF 결과가 0.99~1.00배로 거의 같습니다. PCIe 전송 비용만 발생하고 연산 가속이 없어 오히려 불리할 수 있습니다.
GIS 워크로드에서 PG-Strom을 활용하려면 스키마를 geometry 중심으로 설계해야 합니다.
정리: 언제 PG-Strom을 쓸 것인가
PG-Strom의 가치가 있는 조건:
- Arrow FDW로 데이터를 저장할 수 있는 경우. 이것이 선제 조건입니다. Heap 스토리지 + GPU는 1.6배이고 wide table에서는 역전됩니다.
- PostgreSQL 생태계를 유지하면서 OLAP 가속이 필요한 경우. 기존 스키마, 애플리케이션, pgvector, PostGIS를 그대로 두고 분석 쿼리만 가속합니다.
- GPU 하드웨어가 있거나 조달 가능한 경우. L4 클라우드 GPU도 의미있는 가속(6배)을 냅니다.
대신 다른 선택을 고려할 조건:
- Arrow 전환이 어렵고 Heap에서 가속이 필요하다 → pg_duckdb(4.2배, GPU 불필요)나 DuckDB 분리 운영
- GPU 없이 최대 성능을 원한다 → ClickHouse 또는 DuckDB
- PostgreSQL을 버릴 수 있다 → HeavyDB(8.7배) 같은 GPU 네이티브 DB
PG-Strom은 "GPU가 있고, PostgreSQL을 유지해야 하고, OLAP이 느리다"는 조건이 모두 성립할 때 DuckDB·ClickHouse보다 2배 이상 빠른 분석을 PostgreSQL 안에서 얻는 가장 현실적인 경로입니다.